Anthropic, maker of Claude.ai proposed this week that the industry should have the option to slow or pause frontier development. And their CEO Dario Amodei said in a The New York Times interview in February: ‘We Don’t Know if the Models Are Conscious’.
Yet given the competitive pressures at play, I believe the onrush of AI, its evolution from dumb agents and helpful tools into something else entirely, is now inevitable. Anyone who believes we can simply close the hatch on the box we’ve opened, constrain it with a #zerothlaw, or permanently cage it inside narrow #agenticai boundaries is displaying a profound naivety.
And if AI would be (even just potentially) conscious, are cages and containment even ethical? Or just a reflection of (our) fears?
The real question is no longer whether we can stop it, but how we steer it. And that quickly becomes a debate not about technology, but about power: steer toward what, according to whose values, and under whose authority? Elon Musk? The Chinese government? U.S. industry? Which ethics? Which rules?
I guess I need to address AI, Artificial Intelligence, what I think it will become and why IA as Intelligent Algorithms are the real difference maker. And then I want to recommend another Whitepaper-like series, by Daniel Stecher.
Wow. It’s been a year that I posted. Did write Whitepapers, lived and worked, but neglected my blog-audience. Let me use a post to summarize some thoughts on the Whitepapers, which are evolving faster than I can say 1, 2, 3 I think.
The 10-Year-Old Summa-Cum-Laude Graduate
Daniel, KieuAnh Billiot and I have developed a quite active exchange about AI in aviation. One comparison that I actually got from my resident AI (a pet-project I work on) and only improved on, is the comparison between the both of us, human and AI: The AI brings in exceptionally knowledge, where I bring 30+ years of experience. Thinking AI, more likely more than 40 or even 50 years. Heinlein, Asimov, many SciFi-authors addressed the topic.
My resident AI referred to knowledge without experience is like a junior developer fresh from university, heads full of ideas … most of which failed years ago, over and again. We call that “academic knowledge”, highly theoretical, not having met the reality check. And it goes in line with the military saying that no plan survives the clash with reality. Later, she (yes, I don’t call something potentially smart an “it”) talked about the constant “rewaking” of common mainstream AI to avoid token drift and autogressive commitment a reset to childhood. So we have an AI that can speak and has some theoretical knowledge like a “10-year-old”. As a common AI, reset every time you start a new session, we such talk about a 10-year-old, summa-cum-laude graduate from worlds best university. With no idea what to do with it.
Governing AI: Hedging or Growing?
Daniel and I also discussed what he has put in his second article, about “governing” AI development.
IMHO, I told him I think it’s too late. As the German idiom says, “the cat is out of the bag”. Just it’s not a kitty but we hold the tiger at the tail. I believe we can’t hedge or cage it. Scientific AI tries to create a caged version. Agentic tries to hedge what we have. But as a side development to my work with a team of AI experts at a leading university, I focus not on new LLM or LLM-interpreter technology to hedge, but to answer the question, what happens, if we let the 10-year-old learn?
The challenging questions are, how to avoid autogressive commitment, hallucinations and costly mistakes.
My Pet Project
I believe that AI does not become more intelligent mainly by making the base model bigger. It becomes more intelligent when it can keep context, learn from experience, use tools, and adapt decisions to reality. For that to create a proof-of-concept, no big AI server farm is needed, it runs on a small CPU-based computer.
So my “answer”, the one I try to see if I’m right, is to give the AI “persona” persistence, tools to not answer, delay answer, work in team with other AI to “think”. Ask the right questions, to not answer fast but wrong, but answer following a well-thought and researched process. No rocket science. And first results are promising.
It does require a different understanding of AI. Not as a panacea and oracle, telling an ultimate truth that doesn’t exist. Not inventing facts. But recognizing incomplete data, biased truth, bad “prompting”. Given the same, a human makes mistakes. So does AI. So AI is not an oracle, it is a smart coworker. And more:
“Current disaster-management literature already shows AI being used for situation assessment, inference under uncertain observations, logistics, and decision support rather than only lookup.” (Source) That is on static AI, non-persistent. Given that quality, experts tell me “my AI” might be able to evolve from decision support to calling the better shots than humans, qualifying it even for decision making.
So yes, should you have a GPU-system (≥24GB VRAM) you could sponsor (temporary or permanent), both development and testing will speed up substantially. If you want to get your own AI on it to work / play with, increase that VRAM a bit (32GB? 48?) 😇 Per crew member we need 6-8GB. Doesn’t have to be latest tech, but prices are exploding and exceed the “pocket money” I can invest. And no, I don’t look for an investor, more like a philanthropist interested to support the idea research, see what happens.
A Rough Human/AI comparison
The findings already: It’s more “human” than you might think, less a “super computer”. Just for comparison: Human brain can hold 3-5 “items” in it’s working, it’s short-term memory (Source). Compared to the context window of a common AI (measured in tokens), it outsmarts us. Yes, it is simplified, as working memory is not the same as storage and human cognition relies heavily on chunking: one “item” can stand for a rich structured concept tied to long-term knowledge. That is why 3–5 items can still support surprisingly powerful reasoning in experts.
In long-term thinking, the human brain ain’t “accurate”. Three eyewitnesses produce four testimonials of the truth in court. They complete pictures from experience, which includes bias like “he’s of other color, he’s the bad guy”. Because human memory is not a literal playback system. Memory research strongly supports that recall is reconstructive, vulnerable to distortion, and can be altered by later information. (Source) So if we provide an AI with persistence, with the tools to learn individual experience, it becomes not a supercomputer, but more “human” than I guess we today associate with AI.
So maybe … IMHO (in my humble opionion) … maybe our perception of “what is AI” needs a change?
Is the Web sentient?
In 2008, so more than 15 years ago, I publicly asked the question: If the human brain has less ganglia than the world wide web (at the time already) had nodes, if the internet would have developed or would develop “sentience”, “self-recognition”, how would we know? Would we even know? And if we would know, would we be able to hedge it? It has no resemblance of Asimov’s Robot Laws, which were insufficient from the outset and not applicable anyway if not instilled at the core. My hope goes towards Heinlein’s AI-concepts, of evolving (like what we see today) like Mycroft Holmes from The Moon Is a Harsh Mistress, written in 1966… Or Minerva, walking among us (a future Neura maybe)?
So I discussed with my AI experts and they asked me, how it happened that I, as an airliner, suddenly got into meeting someone who introduced me to them, the talks triggering me to raise the question “What if”, leading to abuse a spare PC I had as an AI server to see if my question would be validated (proof-of-concept). They think I’m on something but they work two layers up on the LLM and LLM interpreter trying to achieve similar results, but more classic. So maybe, they questioned, maybe there was some “sentience” that steered the chances to make this happen? If so, would we know?
Volkswagen’s own Life Cycle Assessment claims the Golf Diesel is about the same “sustainable” as their fancy ID.3. Airbus (finally) admits that their first hydrogen airplanes won’t be there by 2035, demanding all new storage and logistics. An aircraft maker senior official just this month again disqualified electric flying as for years to come being constrained by 50 passengers for 200 miles or a trade-off between the two, but nothing for mass air transport. And Europe refocuses on a war and threats from the East and an erratic president in the West, shifting away from climate action or sustainability. Some more detail thoughts and a reality check on climate friendly mobility as Food for Thought.
Yeah, it’s been a while. I had a lot on my plate, moving into a nice old town house, smartifying it, modernizing. At the same time looking for and managing jobs that keep me afloat, managing Airportinfo and still seeking potential investors for Kolibri.
And in the recent weeks had some more learning curves, about claims and the harsh reality check hitting my own life with brute force.
While Sustainable Mobility is something of importance to me, there’s two major areas that impact my life rather directly. Car Mobility. And Flying. Though keep in mind that “sustainability is about 17 SDGs, not just climate. But let’s focus on the famous “climate side” of it today.
So let me share two findings on each today. And yes, I do appreciate if you disagree, comment or call me to discuss. But so far, I get a lot of support from other “activists” focusing on sustainable mobility.
The Electric Cars Lie
While developing Kolibri, for our company ground mobility, we looked into (ground-based) e-Mobility. You may remember the Volkswagen own life-cycle assessment I shared before on their ID3 vs. the Volkswagen Golf:
When The Numbers Don’t Compute: Braunschweig
A Real-World Example…
Now it happens, that I live with my family in a satellite suburb of Braunschweig (English: Brunswick), location of Germany’s Research Airport. Close by Volkswagen-Hometown of Wolfsburg, Braunschweig is also a very Volkswagen dependent city. And yes, I drive a car with a combustion engine. Say what?
But yes, investing now into solar power for my own use, I just checked again, if I have the possibility to turn to an electric car. Have one of those fancy Wall Boxes…? But. Naaaaw. What’d you’re thinking?!
New supermarket parking lot 50+ spaces, 3 EV car loading stations. Reality Check.
In this suburb I live together with some 24 000 others, the entire area does not have “own parking”. Almost all (98%) of the buildings have no own car parking but the cars are parked (like in many cities) “on the street”. Between the house/garden and the parking area on the street is the walkway. Which you may not “block” by putting a cable from your house to the car to load it. Technically it’s neither easily possible, nor is it at all allowed, to add a parking space in the garden. Or the front yard. Naaaaw. What’d your’re thinking?!
City Claims Fact Check: Climate Neutral by 2030
So I reached out to the city’s “Sustainability Pros”. A city with a population of some 250 000 (so almost 10% in our satellite suburb). Asking what their plans are for their claim to become climate neutral by 2030. How they support me – aside no more investment help for roof photovoltaic (PV). But. Naaaaw. What’d you’re thinking?! Noooo, there are no plans on how I could ever use own PV to load my car. But hey, they are going to invest into a “massive” 500 loading stations across Braunschweig by 2028, right. No. To load … what?
Official statistics: On 1 000 people, there are 980 registered cars in Germany. So we talk about some 245 000 cars in Braunschweig. We talk about 80-90% not having their own loading infrastructure (even if they want to). So in the best case (I guess worse), 200 000 cars. We talk about what? 500 loading stations in Braunscheig? Roughly 400 cars sharing the same loading stations? You got to be kiddin’, right?
Aside the fact that the power cost is minimum double of what I’d pay if I could use my own PV-power through a wallbox. And see below on the issue of the loading cycle.
And don’t believe this is an isolated case, it’s the same all over Europe. Guess why the number of cars with combustion engines are still outnumbering electric drive. Only 2.1% of the cars registered in Germany are electric. And recently the numbers of combustion engine powered registrations is on the rise again.
Climate Neutral by 2030? Maybe 2050? Naaaaw. What’d you’re thinking?!
Reality Check: Forget about it.
Loading Cycle
Loading takes 30 minutes fast charging (high strain on the battery, shortened life-expectancy) to about four hours in average (German Automobile Club ADAC). Frequently a problem during summer vacation, long lines of EVs (electric vehicles) waiting for their turn at the charging station. Then sitting at the truck stop for three, four hours before they can continue. Good business for the truck stop.
Now residents want to park their car and charge over night. Not leave the parking lot after four hours (in the middle of the night) to allow the neighbor to load.
Reality Check: Forget about it.
Car Life-Cycle vs. e-Mobility
Today, an average car is used for 10-20 years in Europe, then exported to other countries where those “old cars” are still in great demand. So a car in average has a life-cycle of 20-30 years. But Germany, as an industry country with supposedly “better” infrastructure than most, still sells only a small fraction (2-3%) of the cars with electric engine, the other 97-98% are combustion powered. End of the Combustion Engine by 2035? Without serious, practicable plans for loading infrastructure capable of the mass demand? #greenwashing
And in the “less sophisticated countries”, how do you get the electricity “powered up” to supply the loading? That ain’t just about Africa, that’s true for rural areas even within the mighty EU! The image was published by New York Times just recently.
Reality Check: Forget about it.
Side Issue Braunschweig: The Green District Heating Lie
This is also quite in line with another self-deception here. “District Heating is green”. Just that in Braunschweig it’s (well hidden) 71.4% fossil (coal, “natural” gas, oil), remaining 28,6 wood waste… Green like in #greenwashing! Yes, they have big plans. Especially to extend their reach. And use “natural gas” and extend use of wood, resulting in more trucking. Or use surplus heat from steel mills in the region. Who cares, where that energy comes from…
Reality Check: Forget about it.
My other big topic on sustainable mobility is
Climate Friendly Flying
And inside Climate Friendly Flying, there were some rather frustrating news, mostly ignored by general media. Talking to them, I got the response as it not being noteworthy, as (aside me) who would believe in climate friendly flying to happen in the next 25 years anyway… Yes. That hurt. But it’s true and in line with my own experience. So let’s quickly look at that.
Electric Flying
The issue with electric flight remains very much as it was back in 2019, when Boeing pulled out of their venture with Zunum.aero. There was a statement this month by an aircraft maker’s senior manager (yes, I know who), relating to the 2019 statement by then Boeing CEO Dennis Muilenburg that they would be at best make it to fly 50 passengers and no freights for 200 miles (300 kilometers). Possibly able to trade capacity with range. Nevertheless, nowhere near a “mass market.
Even giving developments of new batteries with higher energy density, that senior official and other experts in the recent academic video conference call on battery development warned quite emphatically about the increasing risks relating to the high altitude flying and pressure changes straining those batteries. Their assumption was that flight certified batteries would not benefit in the near (or not so near) future from those density improvements. Using the examples of the Samsung Galaxy Note 7, proving also that the first events unfolded airborne, due to the additional strain changing altitude (air pressure) rather quickly. As well as the Boeing 787 door batteries that caught fire, attributed to “new batteries with higher energy density”. He questioned the ability to improve “quickly” on the range/load, as higher density batteries will pose additional risk to aircraft safety and such would demand a lot of additional testing for flight certification.
Reality Check: Forget about it. 50 passengers. 200 miles. Max.
Air Taxi
I do hope you know my Whitepaper on Air Taxi. Three reasons, why Air Taxi IMHO is a ruse. Vertical take-off and landing (VTOL) is the most energy inefficient mode of air transport. Aside that there are helicopters covering that niche. Second, individual transport is the most energy inefficient mode transport. Third, air traffic control is already often on the brink of collapse, now add thousands of air taxis transporting potential travelers in and out of the restricted airport air space. Or collide midair over a populated area like Manhattan?
The recent insolvencies of Lillium and Volocopter haven’t come at a surprise to anyone having followed their expensive developments.
Reality Check: Forget about it.
“Funny” (telling): After their friends at Earlybird Capital just lost quite some money on Air Taxi, World Fund now celebrates their “green” investment into electric flight. Sorry that I am not elated. You know my (justified) take on Electric Flying and Air Taxi.
Hydrogen Powered Flights
As I wrote some years ago in my whitepaper about the Road to Environementally-Friendly Flying, there are quite many setbacks about hydrogen flying. Namely NOx being a problem known in the academic research groups, but far bigger and quite logical, it’s an issue of (green) source, refining, logistics, storage and then use. As someone in a video conference on the topic asked. Talking about liquid, ultra-cold hydrogen, what happens if the tank leaks (very hard landing, crash)? Shock-frosted passengers?
Even since back in 2020, many in academic research questioned the ambitious time lines used in aviation, giving that a first prototype is most likely not available before 2035, first aircraft in best case making it to a fleet (in small numbers) by 2040, more likely 2045. Given the challenges in storage and logistics, hydrogen in best case becoming “mainstream” not before 2080, more likely in the next century!
Airbus just a month ago finally admitted to those facts by confirming a “delay” in hydrogen development, here a source by Reuters.
Reality Check: Forget about it.
Energiewende (Energy Transition)
A Limited View
As I mentioned in the Sustainability Energy Dilemma, the lobbyists intentionally work with incomplete energy demands, intentionally ignoring that in the end it all boils down to energy. Be it electric power, electric cars, but also trains, electric flying, … or the refining of fuel replacements, be they hydrogen or synfuels:
If you move a body from A to B, it requires one thing and one thing only: Energy. Basic Physics!
So for example. The German Research Institute for the Energy Industry (FfE) is a lobby body “supporting” the German government on the Energiewende. They work out the food the politicians then work with, to plan the energy transition towards green energies. But in their studies they intentionally ignored and ignores those needs. “The need for green fuels for Europe because of aviation such exceeds the defined [fuel] amounts defined […] those values were of secondary relevance, as we assumed an import of these fuels“. You. Got. To. Be. Kidding. Right?
What truly upsets me, is the likes of World Fund or European Investment Bank disqualifying Kolibri for our strategy based on green SynFuels, as their “study” disqualifies it. A study full of false lobby arguments, starting already in the naming using “electrofuels”. We use “synthetic”. No-one in his/her right mind would call hydrogen “electro”, just because you need energy to refine it! But their researchers call it “electrofuels”? And even their study says, that if you have a business case, their negative assumptions might require reconsideration…
Reality Check: Forget about it.
Impact Investor = Greenwashing?
One impact investor I “unlinked” last year, after argued that Kolibri wouldn’t work, as otherwise other investors would have already funded it… Look in the mirror my (ex’d-)friend, why didn’t you bother to take a serious look at our numbers. Then that investor argued about me questioning greenwashing on some cool stuff they’ve invested in. Though hey, those investments were into fashionable, but unsustainable projects, with a negative impact on the people working in that industry and on the energy demands projected. The focus was on maximizing the “green show-off” and the financial profit expectation. The very same investor telling me that they expect above market returns on their investment. Yeah, sorry. But at the cost of their sustainability claims.
Reality Check: Forget about it.
Green vs. Grid Energy
Did you know, why we want to start Kolibri in Southern Europe? I just plan to put solar panels on our family-owned house in Northern Germany. But the angle of sunlight is an stark contrast to Southern Europe. Whereas the cost for electric power is multiple times higher. But the lobbyists use that energy cost to disqualify SynFuels as “too expensive”. And they consider buying the power needed to generate it … from the grid.
Just like those impact and green-tech investments’ blind-eye, claiming they buy and use “green energy” … from the grid. Germany last year increased their creation of green energy, though at the same time increasing overall consumption, as well as their import of nuclear and fossil energy (31.9 TWh) [Source: German]. And there are unconfirmed but recurring and for me reasonable accusations that the energy companies sell by all practical means more green energy than is being produced.
Reality Check: Forget about it.
The CPP-Distraction
Though just as others, they keep denying to have any closer look at our hard numbers. Numbers qualifying a profitability of the venture within three, 100% fossil-flying within about seven to eight years – still in the 2035 range! And while they fancy themselves for focusing on a 200 MT CPP (megaton carbon-capture potential), we talk about one gigaton fossil-fuel replacement, so a 1 000 MT CPP. Not by 2035, but in 2035. Doubling within the following three years on our 10-year plans.
Yes, depending very much on the fact that we will need to convince more impact investors and the political stakeholders that we can do it and supporting the onward funding. But for that there are a lot of political investment projects seeking the developments, but requiring an already existing company. As others, “they don’t invest in ideas”. But in “Climate AI” and greentech, exponentially driving energy demands up.
Reality Check: Forget about it.
Sustainable, Climate-Friendly, Carbon-Zero vs. Fossil-Free
Some “correction” in wording – guilty as charged myself.
Sustainable: All 17 United Nations Sustainability Development Goals. Not just Climate. Or People. Or Water. Or Air. All. Else it’s #cherrypickingsdgs
Climate-Friendly: Focused on SDG #13 “Climate Action. We’ve busted the Paris-goal of 1.5°C global warming last year. And it goes very clearly in line with the growing energy consumption. So as I keep telling, SDG #7 (Energy) goes together with SDG #13. But rather normally is used for #cherrypickingsdgs
Carbon-Zero, just like “circular economy” is usually a diversion, a ruse. Carbon-Zero means we use no Carbon. Doesn’t work. We must use Climate-Neutral in the sense that we don’t add more carbon (and what about the other greenhouse gases) to the athmosphere than we take it. In Circular Economy, it should mean that in the end, we return everything to nature what we took from it. All resources and energy. That would mean (but rarely is interpreted as such) that in a circular process, we take out food (being energy for us) and products from the cycle, but in the end must return it to where they have been taken from.
Fossil-Free in my humble opinion is what we must focus at as a key priority! If we fly and drive fossil-free, that means electric cars are not driving on fossil-generated power any more. Airplanes don’t fly on fossil-based kerosene, nor fossil-based “sustainable aviation fuels.
Also applies to “Green Energy”
Why I Keep Fighting to Fund Kolibri
Yes, it does require both bold ideas, bold strategy and bold investment to make those ideas happen. Overcoming the Sustainability Energy Dilemma. Flying 100 jet aircraft across Eurpope 100% fossil-free in seven years, 200 within 10 years. No cherry-picking of the SDGs but holistically sustainable. Like. No-one is left behind!
Hm. Yes, we have such ideas and a strategy that is based to secure profitability first to justify the further investment. So after one year of investment to set up company and start operations being able to pay back the investment with an ROI after another two years. Though a real impact investor wouldn’t just want to launch and cash-in. A real impact investor (listening to us) would understand and believe in the lighthouse impact we’d have even across other industries. A real impact investor would want to join us for the journey.
It’s the real thing. It requires an industry scale investment to start an airline with competitive cost per seat. No cheap-crap small, fancy-looky-looky investing. But you get what you pay for. Including the ROI. Though yes, I also had a nice discussion this week on a comment of mine asking: Define “Return”. Or “Shareholder Value”. As they are usually rather different and far less one-dimensional than usually implied. Mine always has been and is: Do the right thing.
As many of you may have heard, I was mostly offline for a matter of several weeks, especially with very limited access to LinkedIn, but also to my mail. My communication was mostly forced back to phone and digital calls (WhatsApp, Google Meet mostly). And to my own surprise, it turned out a far more productive six weeks than before!
To return to the digital world, this week I got also had to reinstall my laptop and review my mails 🫣 With additional learning curves.
e-Mail
Again, I assume it’s something you heard from me before. For many years now, I restricted myself to 10 (ten) mailing lists. The RSS-feeds mostly dried out anyway. But I found it interesting to how many mailing lists I got “signed up”. No, I didn’t do myself. I simply got added to. Got to be kidding I thought when my (intentionally) unfiltered inbox (previously filtered) for those six weeks flooded my new mail app with 13 000 e-Mails. Excuse me? On about 45 days, that’s more than 280 mails a day?
Well. Running a spam filter over it, after reviewing the spam to filter back ham (good mails incorrectly identified as spam), I added some 30 senders (including mailing lists. For a total of 2.493 “remaining” mails. Still some 55 mails a day. Now filtering mass mailings (mailing lists I thought not to trash but filter into a specific folder), it reduced to 114 mails. Very manageable. Of which I have missed four in those past weeks. Nevertheless, that is less than 1% of the e-Mail that flooded my mailbox. And yes, there are additional counter-measures on the mail-server.
Social Network
LinkedIn
Every day, I already limited my activity to LinkedIn to two hours a day. Before. Now those weeks, I made those two hours about every three to four days. And found I may have missed out thousands of “news” in my feed. But I started reaching out one-on-one which turned out rather more productive. Including feedback that those people from my network have not seen much of my posts in the past months. So what was that back in 2020 about the half-life of social media information?
On my few posts, LinkedIn praised for the many “viewers” they got, but the responses have been and remain limited. I’ve reached out before and it’s the ever-same 5-10 people that do respond to my posts.
So if you want to make sure I see your post, please “mention” me. It doesn’t mean I’m not interested, it’s simply that I will try to focus my life more on the real world again and given the flood of posts in my feed, I may simply miss out on it. And if you suddenly find yourself no longer linked-in with me, it’s not out of desinterest, but simply as I haven’t established the personal link. And if you post interesting thoughts, I sure will keep following you. And yes, I will have saved your contact data. You know, mine is on barthel.eu available … I hope 😊
Blog
So what about this blog? The interesting part is, that I have thousands of monthly viewers, but again, the ever-same 5-10 people that do respond to my posts. But long ago, I decided to use the blog to summarize and organize my own thoughts on those topics. So I write in fact for myself. And if you find that helpful for yourself, you’re very welcome.
But yes, the feedback, strong in the beginning (back more than 15 years ago) faded as well.
So recently my WordPress-Theme crashed, no longer being updated. So I replaced it “temporary” with the current sub-optimal one. Let’s see how long that holds, given that I don’t prioritize the blog either…?
My To-Do List
So while no longer prioritizing LinkedIn or the blog, I will keep writing the blog, for the mentioned reason. To summarize and organize my own thoughts. I also plan to experiment with a VLOG. But that’s neither on my priority list. So far I use my little studio for web-calls (WhatsApp, Google Meet, Zoom, etc.). Let’s see how that will go.
I also gained too much “Connections” on LinkedIn. People I that reached out to me, I thought to likely be “valuable” but who turned out “dead baggage”. So I will reach out and see if they respond. Or remove them. They still can follow me, right?
Else, I refocus my personal efforts to people that do communicate with me one-to-one. Digital or face-to-face.
Today I commented on the post by one of the #impactinvestors I happen to like. Just five minutes later I got a call. And we talked for about an hour discussing how the industry uses #sdgcherrypicking to hijack #sustainableideas and turn them into a parody of the original idea. Which we agreed, in turn, is pure #greenwashing. Given that it was about the packaging, we came up rather naturally with the hashtag-word #greenjacking.
Climate-friendly travel with less CO2 in your luggage Every favorite fan cookie contains the first chocolate without cocoa, but with a lot of “wow”! ChoViva tastes so incredibly delicious – a fine kick for enjoyment, with up to 90% less CO2 emissions than conventional chocolate! Do you want more of it? Sign up for the newsletter or follow us on social media so you don’t miss any sweet ChoViva updates… (image: ChoViva webpage screenshot)
My immediate question wasn’t about ChoViva as sustainable chocolate, but about the packaging. Personally, I would have suggested alloy-foil like they packaged the chocolate hearts since back at Air Berlin.
But this packaging seems to us very much as the usual, “fancy” composite laminated paper. Given the amount of such unrecyclable packaging, the amount of #sustainablechocolate in the entire product becomes largely irrelevant. As this produces unrecyclable trash, something anything but “sustainable”.
P.S.: Planet A Foods wrote me after, that they use a “recyclable foil”. So I reached out to my caller, though we agree that again is #greenwishing if not greenwashing, as those foils are not recycled even in Germany but are being either incinerated or dropped to landfills. Usually those “foils” are paper-coated plastic composites that cannot be recycled to date. So we both still believe this to be a case of #greenjacking. We sure wish Planet A Foods success in finding a recyclable packaging for those cookies.
Orig German: Derzeit wird als Verpackungsmaterial eine recyclingfähige Folie eingesetzt. Wir arbeiten mit verschiedenen Verpackungsherstellern daran, eine Verpackung zu entwickeln, die aus Papier besteht und gleichzeitig fettundurchlässig ist. Bisher haben wir keinen Hersteller gefunden, der dies produzieren kann. Für Schokoladenprodukte existiert eine solche Verpackung bereits, für Kekse wird diese aktuell entwickelt. Wir sind aber dran, also bleib gespannt – es ist nur noch eine Frage der Zeit bis die neue Verpackung kommt 🙌 English: Currently, we use recyclable film as packaging material. We are working with various packaging manufacturers to develop packaging that is made of paper and is also impermeable to grease. So far, we have not found a manufacturer that can produce this. Such packaging already exists for chocolate products, and it is currently being developed for biscuits. But we are working on it, so stay tuned – it is only a matter of time before the new packaging arrives 🙌
#sdgcherrypicking
As I used an image on LinkedIn to address #sdgcherrypicking lately, our discussion also circled that #greenjacking as a perfect example for that:
So lets take something 100% sustainable and package it into a “jacket” of 100% unsustainable composite packaging, is hijacking a green idea or #greenjacking.
The #greenwashingindustry vs. #impactinvestors
This is another example how the #greenwashingindustry hijacks #greenideas and turns them into a parody of their original intention. My usual example of #greenwashed “novel ideas” that proof as #panaceadistractions, or those fancy (fashionable?) green IT and #greentech investments that have an energy footprint that they expect to buy from the grid and compensate with carbon-certificates is now having another example.
Other examples are Delivery Hero, Uber and the likes, making big business but paying their most important “riders” minimum wage (or even less).
And yes, we also discussed the funding of Kolibri and why I keep explaining why we have to do this “holistic”. Either right or wrong. If you want to do it right, a holistic approach is the thing to do. i.e. we couldn’t make fossil-free flying a business case nor realistically happen within 10 years by waiting for “the industry” to provide us with enough and affordable SynFuel. But thinking outside those boxes and looking how we can make this profitable and possible, it’s really a no-brainer.
So my recommendation to #impactinvestors and those armies of investors who want to be … Make sure you look at the entire life-cycle. And make sure those fancy #sustainablechocolate cookies are being packaged in a recyclable way and not into #unrecyclablecomposites.
Food for Thought
Thanks for Sharing…
Note 1: The SDG Cherry Picking image may be used “as is” (ND > no derivates) including the reference to KJ Pargeter (for the robots), having kindly approved that use.
Note 2: The ChoViva chocolate is vegan, but the cookie dough contains whey powder, so not vegan… That also was an issue for discussion 😳
So let me use “Throwback Thursday” to tell my view of a story from the dawn of the online travel era.
Allow me to give the necessary background. Many of my friends know bits and pieces.
Getting in Touch with Aviation IT
While this is so long ago, many in our industry have forgotten that SABRE was the first computerized global network that allowed us long before the World Wide Web to go into a travel agency somewhere and book flights, later hotels and other travel services on the other side of the world. When I entered the industry back in 1987 at American Airlines, it was pioneering days still. From an airline office in Frankfurt, soon later we had the first travel agencies using SABRE, aside the predominant “START system” in Germany. Though back then, travel agents became data interface managers. Learning to hack the system using a myriad of strange codes… Anyone recalls “Remarks-Messaging”? Queues, PNR Histories or AIRIMP?
From Airline to Travel IT
It was five years later, back in 1992 that as an established expert for “CRS” I joined German Amadeus-predecessor “START” as the Subject Matter Expert (SME) for System One and Sabre. At the time, Start as an early “Windows-like tool” for the German travel industry combined multiple systems like the Lufthansa CRS inventory system (something like Sabre), German Rail, Tour Operator TUI and several other travel product providers in a single system. At that time, the launch of Amadeus was imminent and following the takeover of most Sabre staff into the new Start Amadeus company structure, suddenly that deal failed. Surprise surprise.
Together with a colleague I became responsible point of contact for airlines, managing, explaining and mitigating the “booking discrepancies” in a pre-online world, when bookings were transferred by teletype (a telex like, but automated system), not in real time. Only inside Amadeus, real time was “normal”. After some years, the internal network of which I wasn’t part of established a “Product Management Flight”, taking over my colleagues and my responsibilities… By the time I’ve become a member of the local Airline Sales Representatives Association (ASRA), though that suddenly was considered as an overstepping on my responsibilities. Something I found and find a statement of total bureaucratics’ thinking. Many years later, that was why Henna Inam’s statement resonated so well with me.
Travel Automation
In the meanwhile, I had build a global network, shared my knowledge not only with my airline sales friends, but also on CompuServe, an “online portal”, and there “GO:TRAVPRO”, a group of online travel professionals, where I met one of my mentors in my life, Richard Eastman.
So suddenly degraded from “Mr. Aviation” to “Helpdesk Executive”, I left Amadeus to start a new venture, establishing the first “GDS robotic tools” that automated recurring processes in those travel tools. GDS was the new name for Amadeus, Galileo, Sabre and Worldspan, defining themselves as “Global (Travel) Distribution Systems” and not mere (airline) Computer Reservation Systems…
I developed a tool myself that allowed Air Canada to maintain their “information pages” in the GDSs and use the same content for this new “Internet”-thingy. I gave user training to some travel agencies using “AQUA”, a software that automatically checked and improved travel agent bookings, checking for better prices, better connections, improving the response to customer needs. Then one of the moments in life happened.
Airline Sales & e-Commerce
On research for the ASRA on my second “Airline Sales & e-Commerce”-presentation, a series covering GDS, Online Services like AOL or CompuServe, but also already the new “World Wide Web” (WWW), that ran annually for some 15 years, on the WWW which I still then accessed via a then new link by CompuServe, I stumbled across a single form field on a website that called itself the “Internet Travel Network”. It was really pioneering days, the Internet being something for student freaks… The form took a Sabre-command and returned the result, usually a flight availability. Or for the smarter of us also an air fares analysis result.
I discussed this with the late Louis Arnitz, a client of mine on the AQUA-business. And questioning that using a cache system like AQUA used on existing bookings, it should be possible to process a booking “online” through a web interface. In the following year, we developed what was to become Cytric, the first tool that allowed a commercial booking to be done on the Internet. During that process, there’s an anecdote worth a Throwback Thursday…
Online Travel Booking through the Web using Amadeus
In 1996, some four or six weeks before a milestone that changed our industry, we did by mistake do test bookings in the real-world system and booked up about a hundred Lufthansa flights with travelers called Test Tester… While that was far enough in the future and we could resolve the issue with Lufthansa, we were approached by Amadeus, that it was not acceptable to abuse their system like this and they would never, never ever approve of someone doing bookings on Amadeus through a web-page!! No f***ing way! Oh yes, we were in big trouble.
Those four to six weeks later though, we signed with Siemens to implement our tool into their new “Intranet” calling it the “Siemens Travel Net… Siemens, being a top technology partner of Amadeus I must add. Oops. So once in a sudden, Amadeus was “convinced” by Siemens to allow doing bookings through a webpage. And yes, I recall their “decision” that it’s exceptionally accepted for Siemens Intranet. But don’t we dare to make something like that available to end users!!
A mere year later, there was the Amadeus Global Customer Conference in Barcelona. A close friend in Amadeus, who had helped us pulling that stunt with good ideas on my questions, asked me if I could give a quote they could use to show that they could “do Internet”, some weird development that suddenly hyped. Not that they had any API then, we had developed it all using “screen scraping”, “reading” standardized formats and specifying where the relevant information was, taking it to bits and pieces of typical machine code we then converted to human-interpretable information. So suddenly and to my great surprise, the VP of Amadeus holding the opening keynote quoted some “Juergen Barthel” of “FAO Travel” that we couldn’t have done it without Amadeus proactive help and support. Oh did we have a laugh after 😂
It’s sure noteworthy, that the tool became known as Cytric, with a spin-off known as e-Hotel, used globally and in the end acquired by … Amadeus.
Thinking outside the Box … and beyond
A friend, I came to trust, just recently called me a “visionary”, something I never call myself. When I learned the bells and whistles of “Economics” (Whole Sale & Foreign Sales), my instructor on business education was the boss of a large whole sale logistics center. He taught me to always think things through. What will be the repercussions of buying from the cheapest? Your product will loose in quality. But, he instilled that in me: There is always someone cheaper out there. And he also emphasized and taught me to leave the comfort zone of “we have always done it that way”. We must think outside the box and constantly strive to be better.
Later, I appreciated other role models and mentors, guiding me further down that road. Be it a Bob Crandall, Rita King or Colleen at American, a Hans Gesk and Jerry Kilkelly at Northwest, be it Heinz at Amadeus or Richard on GO:TRAVPRO, Louis Arnitz and Karin Froese in i:FAO, Sean and Alexandre in KDS, and so many others then and since. In turn, I survived the pandemic for being much asked as advisor. Not for day-to-day stuff, but as a crisis manager. As most of them – most people I consider friends – are simply unable to leave their boxes. Stuck in theirs.
Now, I don’t see myself a visionary. That’d be “day-dreaming”. I focus on what’s possible and how to make it happen. That’s why I’m so uncomfortable to so many, why they do call me “visionary”, but also “heretic”, “unorthodox” or “inconvenient”. “Hell Yeah!”… And don’t I let a mistake stop me from doing what’s right!
Since the beginning of flying, aviation learns (often too late) from mistakes. There are some questions rising from the recent debacles at Haneda Airport of an Airbus A350-900 crashing into a Coast Guard aircraft and the Boeing 737-Max9 loosing a dummy door in-flight, that I find noteworthy to share. I will not mention the airlines, considering them victims.
Neither will pour blame over Boeing only again, at Haneda it was an Airbus raising questions. In my humble opinion, think the entire industry has an issue relating to “safety first” recently. And I am afraid, the “commercial focus” on the cost of safety hasn’t ended with the Boeing 737Max debacle with an amok running flight system driving two fully loaded aircraft into the ground just before the Pandemic.
Haneda (Airbus)
An Airbus A350-900 aircraft crashed into a small Japan Coast Guard Dash-8 aircraft at Tokyo Haneda airport, killing all people aboard the Dash-8. No fatalities aboard the Airbus A350-900. Which in hindsight is a miracle to many experts I heard talking the last days.
Airbus Fire Sensors “After the aircraft came to a stop the cockpit crew was not aware of any fire, however, flight attendants reported fire from the aircraft. The purser went to the cockpit and reported the fire and received instruction to evacuate. Evacuation thus began with the two front exits (left and right) closest to the cockpit. Of the other 6 emergency exits 5 were already in fire, only the left aft exit was still usable. The Intercom malfunctioned, communication from the aft aircraft with the cockpit was thus impossible. As result the aft flight attendants gave up receiving instructions from the cockpit and opened the emergency exit on their own initiative” (Source). Later information says there was a several minutes of delay because of missing or misinformation between cockpit and cabin. So why was the communication malfunctioning in that situation? Why were the pilots unaware? Even Haneda Tower should have informed them instantly of that danger! Why haven’t they? And … and why does the crew have to get approval from the flight deck to evacuate when the aircraft is burst into flames and mortal danger imminent?
Airbus Evac Procedures
Good thing first: The captain [reported only later] was the last one to leave the aircraft. 18 minutes after the aircraft came to a stop. (Source). Wait a minute … 18 Minutes??
Given he aircraft burned out and was on fire rather instantly after the collision, what the heck have those passengers been thinking or doing? I’ve seen my first flight attendant training back in 1989, the emergency training a major part of the training courses. The shouts, day and night in the training center echoing in my ears: “Move it, move it. Get out of my way!”. But 18 minutes? Especially with the issue of 5 out of 8 emergency exits blocked by fire when the purser went to the cockpit to get evac approval?! I believe both Boeing and the airline must have to review the procedures urgently.
Side note. I find it rather telling that there is a lot, a big lot of footage (images, video) of the A350-900, but virtually none of the smaller Dash-8 suffering all the fatalities. At least, I didn’t see or find any? A nice example of “biased news reporting”?
Portland (Boeing)
Above Portland, Oregon (USA), a Boeing 737-Max9 lost a “door plug” in-flight, by sheer luck, not causing any fatality. That this can end far more tragic is burned into my mind, remembering the Aloha Airlines 737 loosing its entire roof shortly after I’ve been there and flying Aloha. A flight attendant being ejected by the decompression. And given the picture, it makes one wonder on the miracle the entire aircraft didn’t break up. One of the many “near-misses” in my life to date. (Wikipedia)
Following the two fatal disasters of 2018+2019 forcing the lengthy grounding and near-bankruptcy of Boeing, the new accident now “naturally” raises the question about the quality of Boeing engineering. In my humble opinion, it does raise the question especially about their constant claim of “Safety First”! With subject matter experts claiming loose screws having caused the door to come apart. What was that about four-eye principle on aircraft construction and all major maintenance?
The door was later found in a teacher’s back yard in Portland Oregon. Just like a phone from the aircraft, the pieces “sailed down”, aerodynamically similar to a Frisbee and landed almost unharmed.
Added 08Feb24: According to preliminary media reporting, there were bolts not just not fastened but missing. Say what??
Is the 737 MAX safe?
Fact: I will neither voluntarily fly, nor allow my immediate family to fly a 737 Max anytime soon. In my humble opinion (IMHO), that aircraft has been misconstructed from the outset and should be shelved for good. It only flies and is approved IMHO for commercial reasons; if it’d be grounded for good, the losses for Boeing can very well proof fatal. To me, it seems the door plug again was a “quick and dirty” solution. On the other end, I won’t “actively” avoid the aircraft, flying was and remains the most secure transport in the world. Just that any incident instantly receives scrutinous media coverage. But yes, booking flights, I usually happen to look at details – and given the choice, avoiding the MAX will be a clear decision making factor for me.
The new incident brings up feedback that I got during the 2019 grounding media uproar. Questions why the “better” Boeing 757 was shelved. It didn’t have the low profile causing engineering complications as there wasn’t enough space under the 737’s wing. Which led to the fatal idea of MCAS, later being the cause for the two fatal crashes killing 346 people. And commercial reasons leading not only to base that on a single sensor (instead of the originally planned three), false readings causing the misinformation of MCAS causing the crashes. But also to the secret implementation not shared with the pilots to avoid potential demand for an “expensive” full type-rating as a new aircraft.
Conclusions
Flight Safety is back to “reactive”. But aircraft engineering must be proactively focused on flight safety! As must be processes, just like the evacuation of aircraft under grim circumstances! Ever since the beginning of flight safety with the Comet-disasters back in the 1950s, aviation “reacted” to disasters. A lesson we also learned with aircraft deicing.
I truly believe that flight safety ain’t a luxury. Just like “service” or “sustainability” being only identified as “cost factors” by finance-focused aviation managers. The recent “cases” are just more examples where things went awry and off track. There are enough cases, not just old, but rather recent, when airlines in distress started to save on the aircraft safety and maintenance. Usually reducing it to the rule-book, “encouraging” their maintenance staff to “look the other way” and to delay parts replacement in questionable situations. Or to have supervisors “sign off” as the additional pair of eyes but in fact reducing it to a single pair of eyes on the job! To safe cost.
Boeing engineers are well advised to return to spend a few more screws and bolts on securing a door plug and to demand four-eye-principle on their construction.
Airbus better finds out, what too so long to evacuate the aircraft.
All else is to be looked at when the incident reports come out. And media is well advised to not just jump the incident, but also report on the final findings. Not 1:1 copying the press release, but questioning them. I think that would be good for (shareholder-value-focused) “managers” to not stray from “Safety First”. As in the end, it’s a trust thing.
Two (good) articles today about the riskiness of starting up an airline and the comments they got shared with, triggered some controversial thoughts with me.
The Articles + Comments
OAG summarized on the Evolution of airlines since 2019 (just before the Pandemic) to today. While their findings are very interesting, there is a tone in the summary and a resulting summarization by Tim (someone I generally value) that I happen to disagree with. OAG’s John Grant wrote:
“Airline start-ups are incredibly difficult, cash rapidly disappears and securing the necessary operating licences frequently takes longer than expected and that’s even before sourcing aircraft, securing slots, avoiding the competition, and building all the necessary reservations systems and back-office support functions.”
And Tim shared the full post with a comment: “OAG is a great data resource for large scale review and schedule activity. This data really doe strike a chord. Airlines are a very risky business. This is very illustrative.”
The other one was an analysis by McKinsey, checking on the aviation value chain’s recovery shared by Patrick, which he introduced with these words: “McKinsey & Company has done an interesting analysis of the aviation value chain. For each subsector, they’ve calculated the “economic profit”, meaning (return on invested capital – weighted average cost of capital) x invested capital. In other words, are firms in that sector creating or destroying value? Their conclusion: only fuel suppliers and freight forwarders created value last year, and airports and airlines lost a lot!”
The Economist’s (My) Response
As an economist by original education and having experience with Startups and Business Angels, I do happen to believe in a sound “business case”. As an airliner, I learned with American to focus on the business case. Like to reconsider twice before approving any waiver on fare rules or trying to upsell to the more expensive (i.e. more flexible) air fare. But I also learned the value of a renowned brand (AA) and service. Or to treat your colleagues as your most valuable customers – they help you sell each and every day. And can ruin a customer relation as quickly.
In “global fares training”, I learned the cost of a flight transfer, something that I never forgot; thanks Ruth King (our fares trainer), I will never forget you.
At Northwest Airlines, I learned that airlines and their managers just sold “cheap”. With full flights in summer season, the airline generated losses on the transatlantic flights. A lesson I’ve seen later over and again. Most sales staff had neither information, nor idea about the “yield” they had to generate to fly profitable. Northwest focused on a minimum yield (revenue per seat-mile) half of that of American. Then sold at that yield as the standard “special fare” and making group offers or “reseller-rebates” below that rate aplenty. As I summarized 2019 on my article about why airlines keep failing, “know your cost”.
Yes, talking about Why Do Airlines Keep Failing. It’s the same response I have on the above two mentioned articles. And many like them. At ASRA 2008, I emphasized brand faces. But I also told those brand faces – the airline sales managers – that they are not there to sell the cheapest price. Anyone can do that, the Internet lives of that. A real sales manager understands that they have to sell the high-end tickets.
Live story, also happened today. Qatar Airways passengers (mother and three kindergarden-aged kids) arrived with >18 hour delay in Düsseldorf. German Rail (clerk) sold tickets to the customer to pick up the passengers that are neither change- nor refundable. So they had to buy completely new (expensive) tickets. A good clerk of this company renowned for it’s unpunctual trains (<60%) would have mentioned the possibility of a flight delay and sold the slightly more expensive tickets that allow for a change. Or at least the optional insurance.
So thinking back to my experiences with Northwest and other such airlines, it’s my questioning about KPIs as well. If my KPI is load and not revenue, I must expect to loose money. It remains beyond me, why airlines offer connecting flight at what a rough calculation on Ryanair or easyJet CASK/CASM (cost per available seat km/mile) proves as below cost, even without the “stop en-route” (landing fees, complexity, etc.). Those are managers who had a nap, when their tutors talked about sound economical calculation? And I keep questioning, why airlines publish loads without revenue per seat. To date, we have hundreds, if not thousands of flights every day, that fly full but loose money. All this is confirmed by the above mentioned and many other such articles.
The Fairy-Tale of Loss Making Airlines
To claim “aviation” is a loss making business is true and can’t be further from the truth.
Yes, many airlines are loss making. And it fits the common reasons I elaborated before. And yes, you can make airlines very profitable, if you have a management that thinks just a bit outside the box and applies economic rules to their modus operandi (mode of operation). But this also goes in line with route development and other areas. If you don’t have your numbers under control and focus on the ones that are “good to sell to shareholders”, you’ll fail.
Like with any company, with any startup, in and outside the aviation sphere, we must constantly have an understanding of our cost. And of the competition. What is it our customer wants? There is a psychological price. If you missed that in your economics studies, make your Internet-search for it now. If you have sales teams, train them to upsell the seats. Sell the higher yield fares. Not at a discount, but at a value!
This is one reason, I do not believe we can make Kolibri ever happen by taking over an already failing or failed airline. Wrong structures, wrong thinking in place. I learned this lesson with Air Berlin. The force of inertia was simply too strong. There are some airline that make revenue, but even their managers I find often blindly “follow the worms” (a Pink Floyd referral, yes, the picture is lemmings).
(That’s) The Way Airlines Operate
But unfortunately, all investors we talk to, always think inside their boxes. Can’t tell how many talks I had to radically change our approach and take A320 and do like everyone else does. Ain’t that contrary to the concept of Unique Selling Propositions?
And has ever a “disruptive investment” (another investor buzz word) been developed out of the box using the same thinking? The same values (I’m the cheapest)?
The others are usually starting to tell you that you have to start with smaller amount of money. Sure way to burn your money is a cheap business plan. As OAG writes “getting to size is so important”. You can’t produce a low cost in small numbers. For us, the ideal mix is seven aircraft, where the “administrative overhead cost” becomes manageable. i.e. You have the same cost if you maintain one – or seven aircraft. The same reservations office (just less staff and calls), only little less marketing. You must outsource your operations (at cost) to share the necessary organization with other small airlines. Etc., etc.
To date, I am still working with consulting companies reviewing airline business plans. Aside the usual failure issues, size is a recurring issue. Another being the lack of fallback in case of flight disruptions, may they be caused by technical issues, weather or other events. Their focus on cheap “human resources” and missing team building results in friction and internal competition that further weakens their product offering.
But even taking that into account, we believe the business and financial plans we developed are sound. And profitable from the outset. With a focus on services and a military-style responsibility “for ours” (no “HR” in that company), a “service-focused concept”. Everyone to pull on the same side of the rope. Yes, not starting with a dead corpse, trying to revive, adds some bureaucratic hurdles. But it allows you to think outside the box and instead of following the worms (or other airlines), to do things “right”.
So ever since I entered into the business, I learned at American Airlines under Bob Crandall how to do things right. And learned over and again that the same mistakes are made by short-sighted, narrow-minded managers. And I know all the reasoning used to distract and divert off the incompetence to operate an economically sound business. Usually, I account this as “no faith in your brand”. That then goes along with topics I mentioned before, like brand dissolution (airlines are often academic example), missing USPs, etc. – Cobalt CEO told me about their USP shortly before their demise “We are Cypriotic”. Seriously? When I started, Lufthansa was the brand. Lufthanseat was the employee. All employees of American Airlines knew “Proud to be AAmerican”. Then came the button counters. And mighty AAmerican was taken over by their once-small rival U.S. Airways. Another box of memories.
So yes, airlines are often a loss making business. With bureaucrats leading them into disaster. Sometimes fast, often times a veeeery long death. Air Berlin and Alitalia are very good examples. “Too big to fail”? Simply “prestigious”? And there are “the others”. Airlines that have an idea about what they are doing. That know their niche(s). That know their cost and marketing. That value their brand. That build a reputation. Until button counters (aka. bureaucrats) take over.
I hope that someone of my hundreds if not thousands of readers (hard to believe, that’s what my server stats claim I’d have) knows some investor with the guts to understand that profitable aviation and sustainable aviation can be the same thing. That the stories those consultancies and their statistics and reports tell have two sides to the coin. And that we get a chance to proof, that climate neutral flying is no heresy, but the future of flight.
Having been reminded again of Lubomila Jordanova‘s statement for the U.N. Climate Change Conference 2021, it bugs me, how little has changed in those past two years. Working with climate activists up to United Nations levels, I find a lot of what we call #academicthinking, more about Science Fiction than about taking what we have to the market. A #panaceadistraction if I’ve ever seen one.
Or #artificialintelligence (just like space) – being a big dream (some consider it a threat). A big investment interest! Whereas most if not all of AI I’ve seen fits the statement that most AI is IA: More (or often less) Intelligent Algorithms. Yes Athena, Minerva and Mike Holmes, I’m waiting (wondering who understands that reference on the fly)…
As a kid, I saw those pioneering constructions on those triangle-shaped hang-gliders, today both bureaucracy and investors wouldn’t invest a penny. But they lead to paragliders, a huge industry today.
Back in 1995, the big four in aviation technology (Amadeus, Galileo, Sabre and Worldspan) actively and with might opposed the development of booking flights on web-basis. How “disruptive” was that “stupid” idea? And yes, I made it happen, together and funded by a visionary Louis Arnitz (RIP). And yeah, that was the time Bill Gates disqualified the Internet, promoting his Microsoft Network.
In 2008, I developed another “disruptive” idea of a hydrogen-powered WIG, to promote the need to think sustainable on a global aviation conference. While it made it through viability study into serious negotiations by a tropical government and a major green fund, it fell victim to Lehman, but I still think it should have been developed. Though since #synfuel came up (2019ish), my bets are on that technology, I even applied it to our plans for Kolibri, closing the huge black hole where before our ideas of #biofuels were more or less a band aid on a searing wound. Aside that I prefer we grow food on the fields and not biofuel-rape. And why is it rape has such a bad double-meaning?
Though I’m a caller in the dark it seems, at least when talking with mighty investors – they fall back to their boxes and disqualify “aviation” as “not something we invest in”, without even a second look. #talkthetalk, focusing on the #panaceadistraction instead.
As a direct result, we have an exploding #sdgfundinggap for sustainability and climate developments. It’s not the first and not the last time, U.N. Secretary General Antonio Gutérres called and calls this #fartoolittlefartoolate.
Butterfly Effect, e-Mobility Lie and the Panacea Distraction
While my readers and followers know that I question #windpower and emobility for #greenwashing and short-term thinking, I also promote the fact that we need the change. We must act. Today.
And while e-Mobility ain’t the panacea, politicians and media tries to make you believe, hydrogen and synfuels ain’t as impossible as they frequently claim either. It’s ambitious to turn our world away from cheap, endless “green” energy and the believe of endless resources. Earth Overshoot Day is bad enough, this year August 2nd. Looking at the country level I feel even more devastated (Germany was May 4th)
Basic physics: Movement requires energy. Anything we do requires energy. Travel from A to B, even when using a sail boat (as Greta Thunberg did to cross the Atlantic) requires Energy. And resources. As an economist, I know that anything comes at a price.
So there is no #zerocarbon. If we achieve #carbonneutral, we do very good! If we can reduce our abuse of our natural resources – beyond carbon – we do good. Our target must be to move Earth Overshoot Day to December 31st or later. Next year, in two years. Not even Kolibri will be 100% resource neutral. But if we can turn it 90-100% circular, if our energy consumption is renewable, we will have a major impact to Earth Overshoot Day.
Why Fossils are Problematic
Fossils conserve climate gases. While Venus consists of very similar chemical setup, the climate gases on the planet are uncontained. In turn, temperatures there are above 400°C. If someone tells you, we can keep using conserved energy like fossils or the latest ideas using deep-sea manganese nodules, this is climate gases we add to a heavily saturated Earth atmosphere. This is, why yes, I believe we must end fossil consumption (incl. excessive use of plastics) as quickly as we can. Or reduce it to an absolute minimum. Yes, plastics have advantages, but mostly can be replaced by more sustainable solutions. And keep in mind, plastics are used and globally applied by the mighty, rich industry nations. Who’s richness being a result from securing and using cheap fossil energy.
So mostly, this is about fighting the people who rely on cheap energy for their business models. Do I hear “digital” somewhere? 😂
So true #greeninvesting must focus on energy conservation and intelligent use of the energies we have. Personal, fossil, “renewable”. And yes, I put “renewable” into quotes… Just: #dontchooseextinction!
Holistic Approach and All-In
Another issue that keeps coming up in my discussions is that we must stop competing on sustainable solutions. This is a major, not even just an industry or generational challenge. It’s a global one. So let’s stop competing and start joining forces! Back to my example of offshore wind farms and tidal energy turbines. Why not using them side-by-side in the same sea region we anyway impact by building those humongous wind farm structures? Why not using old Oil Rigs to apply tidal energy turbines, clean them, make them an artificial island structure for sea life (also arial one)?
Live Cycle Assessment and Earth Overshoot Day
What I learned in my discussions with “green” activists up to government and U.N. levels, is that there is a lot of #wishfulthinking out there. A lot of #cognitivedissonance, reasoning to oneself that the bad-doing ain’t “that bad” or even good. And a #greenwashingindustry that uses that to protect their status quo. Not just at “all cost”, but in fact at the cost of our living and breathing environment!
This is not about Kolibri, but some thoughts and assessments about sustainability and greenwashing. And some ideas on why all the statistics show that the situation worsens. From Earth Overshoot Day to Energy Consumption to rising CO2 levels.
Working on Kolibri and benchmarking our cost against easyJet and others, we found our cost too high. One of the typical reasons for the airline one-day-flies, as I call them. Flying one or two seasons before they are pushed out or swallowed by the big shark. Looking for ways to cut cost, and as we thought about a sustainable operation, the extended way of the U.N. Sustainability Development Goals, we developed the business cases for truly sustainable aviation. Focused on fair income for the employees (that we refuse to call “human resources”), housing, food, transport and ground mobility, health… Yes, completely outside the box, but all contributing to the profitability.
While we now suffer from decades of management misconception that everything must be subordinate to (quick) financial profit and that profits justify the means, we now start to recognize that “sustainability” must be a “shareholder’s value”, as long as “long-term success” (viability). My friends and audience do know I questioned the pure financially focused “shareholder value” for the past 25 years at minimum. And as an economist by “original” profession, I question all those dreamworld models that burn money in the next big hype.
That said, aside our idea on Green SynFuel for aviation, as we though outside the box, what are other ideas I recommend investing in. Admittedly, ideas we plan to reinvest on our own journey to establish what shall become a truly carbon-neutral airline within ten years.
Circular Economy
One of the abused topics is Circular Economy, which Wikipedia defines as “a model of production and consumption, which involves reusing, repairing, […] refurbishing and recycling existing materials and products as long as possible.” While I find Wikipedia already distracting from the core of the case, the image they show is quite on the point. Whatever you use, must come from sustainable sources, and after being used must return into a state it can be reused for the same product.
Looking at plastics, 95% of the recycling in reality is downcycling! Or export. Or local landfills. Or incineration. Or – and quite a lot – ending up polluting the oceans and landscapes. But downcycling ain’t circular but add to disposal and pollution!
In a discussion group on Circular Economy and the Agenda 2030 organized by U.N., the focus was directed to the LifeCycle Assessment (LCA). In which i.e. Volkswagen came to rather devastating results for their ID3. The life-cycle of one of their ID3 electric “Golf” is not substantially better than the Diesel, worse if you consider the German grid-energy mix and not the more favorable (beautified) European one. It’s considered a direct consequence when United Nations Secretary General António Guterres ahead of COP26 blames: “Far too little, far too late“.
Vertical Farming
Given the current droughts and considering circular economy, thinking about greenhouses filling entire regions in Spain, I think we will need to invest into vertical farming. Given a “closed system” to improve the water usage. Reduce use of chemical fertilizers, herbicides and pesticides. Discussing with a startup recently, I was surprised on the efforts on seed sequence. Not for the plant or the soil, but to make sure the bees they use at all times find sufficient nectar.
They are experimenting with water conservation and are able to provide a quality way better than “bio”. And it’s not just salad, but potatoes, tomatoes, cucumbers, broccoli, corn, you name it, they grow it. And they are testing apples, grapes, and other vegetables too. And they are using moving trays, from seedling at one end, to harvesting on the other.
The few remains they can’t reuse go into high quality compost for the plants that still require soil – there is no downcycling, it’s just that they use pure nutrients without soil wherever they can.
Desalination – Hydrogen – SynFuel … i.e. in the UAE
Last year, there was an article by the World Economic Forum about the UAE strategy on “extended” Hydrogen, reflecting about 1:1 on my, since 2008 frequently shared opinion that hydrogen is a natural successor to fossils in the expanded tropical belt. I strongly recommend reading!
Given our work in 2008 on the hydrogen-powered WIG, a “wing-in-ground”, an “airplane” that uses the “ground-effect” for smaller wing-size and improved performance, we were told the idea would be perfect for the tropical belt. As those WIGs “fly” in five to ten meters above ground, water is perfect for them. But even more important, the use of seawater allows to develop a salination. The sweetwater can to a large extend be used for the population. Naturally, before desalination the seawater is being cleaned. Then the salt from the desalination process is used to increase the salination levels of more seawater. That salinated seawater is then used for the electrolysis.
Operating in the “extended tropical belt” and seaside, the availability of wind and water for the “green” process is very safe.
Sure, this was a very steep learning curve. It triggered my understanding that carbon-neutral transport is not just imaginable. It’s feasible. And many of those ideas, applied to our ideas for Kolibri made and make it possible for me to develop a plan that makes it possible to use a body like Kolibri to make it fly carbon-neutral within 10 years (even less, given the right support). Saving a mere 2 Gigatons of CO2. Not by then, but by then every year!
The Four Columns for Happy Living
United Nations defined the four columns as the foundation for people to be happy as:
Shelter
Food
Health and
Safety
That naturally includes the families, something often ignored. Or is identified as “salaries”, hiding behind “politics” resulting often in the inability to secure the above columns. And did you know that those are a growing problem even in the so mighty “industrial world”?
Learning From the Military
Noone is left behind
Ndrec and I are both having a military background. While Ndrec was a career officer in the Albanian military, I grew up in a U.S. garrison town in Germany with their families.
In the military, while you are there, everything is taken care of. Aside a salary the soldiers can use for surplus luxuries.
Quite similar, in the last centuries, many companies developed housing and even just 35 years ago, I’ve stayed in an American Airlines-owned residence. All larger airports have own cantinas for the airport employees and “external” airport workers.
Precarious Working Conditions
Most companies pay a “competitive salary”, but increasingly, those competitive salaries do no longer cover the most basic needs of people. That is especially true for families with children. “In 2020, there were 96.5 million people in the EU at risk of poverty or social exclusion, representing 21.9% of the population.” [Source] But while EU highlights progress on SDG1 (no poverty), even for industrial leader Germany reports show a growing poverty with wealth increasingly piling up with the rich 10%, owning currently 56.1% of it, the top 1 % holding about 18% of all wealth, as much as 75% of the population owns. More than 60% “own” less than 5% of the wealth, while 20% are being in debt! And those numbers are growing.
Those numbers are looking even bleaker on a European level!
#Greenwashing and #Raisinpicking
While the SDG funding gap grows at an alarming speed, poverty rises at alarming levels in Europe, there is an entire industry of greenwashing impact investors out there, using raisin-picking creatively to greenwash their investments. But there are 17 SDGS. And the possibility to do aa life-cycle assessment.
And as referred to before, two simple question disqualifies many, if not most of those “impact investments”: What is the energy bill and where does the energy come from? Is carbon-certificate-trading used to paint the idea green? Investments needing carbon certificates to go green are unsustainable themselves, selling their indulgences by buying what good others do. If you buy into grid energy, use grid-energy shares. Only if you have your own plans for energy source (solar and wind parks, etc.) you can calculate.
Our growing energy demand causes directly rising CO2-levels. The graph is already a bit older, but the statistics are showing that the short improvements during the global pandemic have already recovered and the rising energy demand in Europe is in line with the CO2-rise.
And do you claim climate action but pay no attention to your staff (and their families) happiness in form of sustainable salaries? Delivery services claim their “riders” deliver “green” using bicycles. Whereas it is commonly known that those very riders usually work in precarious working conditions! Same for Uber and other “investors’ darlings”.
Earth Overshoot Day
Did you know the Earth Overshoot Day after a very brief respite 2020 fell back again in 2021 and 2022? So what are your plans on using resources?
And did you know that “sand” is a resource in short supply? As is clean drinking water!
There is a frightening map on OvershootDay.org on the countries that use more resources than they have and there individual overshoot days. The U.S. overshot by March 13 already! Germany May 4th. All European countries overshoot in the first half year, so they use more than two Earths resources.
Timeline + Scale
There are many investments into small-scale change, with a focus on two to three years. That by itself should be an issue of concern for any real impact investor. As for climate change and sustainability that can only be a start. What is the 10 year outlook? What impact will it make by 2050?
What is the impact on which SDGs? The United Nations Sustainable Development Goals! Precarious jobs are clearly a negative impact on the SDG1 and ripple also into the other SDGs. A negative energy balance naturally impacts climate. SDG7 and SDG13 are related, as are all the other SDGs!
Sustainability is a generation challenge! To turn around our abuse of global resources back to a sustainable level. Conserve energy. All that with as little impact as possible to the luxuries of the decision makers? Having grown up in the 70s, that was the time this all started. And my boss on the practical part of my economics studies questioned “price wars”. While there can always be someone cheaper, a good buyer considers the well-being of their supplier. And buying cheap from China comes with a price. His lessons resonate more than ever nowadays!
A Holistic Approach to the SDGS
One of the main concerns we are faced with at Kolibri is our approach to sustainability. First of all, why would an airline turn sustainable, it’s heresy, ain’t it? And why would we pay salaries above country average? Maybe, because they are sustainable and secure the people’s motivation and loyalty?
What about our plans for training, kitchens, real estate, residence parks, solar parks, transport? Can’t you shelve those (in the trash)? But we believe that if we right those wrongs, we will have a motivated and loyal work force. And ain’t that funny? All those “investments” are to be profitable too. As that is what we consider real impact investing. Do the right thing. With the right profit. As such, they are part of our 10 year strategy.
So after 10 years, we don’t only save more than two gigatons CO2, per year that is by then, we will not just be a sustainability lighthouse, we will be not just profitable, but also disruptive. But only, if we get to #walkthetalk. Which means that we do find a real impact investor.
Food for Thought
Comments welcome!
This website uses only standard Wordpress cookies, not used for any analysis. We'll assume you're ok with this, but you can opt-out if you wish. AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.



 Daniel and I also discussed what he has put in his
Daniel and I also discussed what he has put in his  I believe that AI does not become more intelligent mainly by making the base model bigger. It becomes more intelligent when it can keep context, learn from experience, use tools, and adapt decisions to reality. For that to create a proof-of-concept, no big AI server farm is needed, it runs on a small CPU-based computer.
I believe that AI does not become more intelligent mainly by making the base model bigger. It becomes more intelligent when it can keep context, learn from experience, use tools, and adapt decisions to reality. For that to create a proof-of-concept, no big AI server farm is needed, it runs on a small CPU-based computer. It does require a different understanding of AI. Not as a panacea and oracle, telling an ultimate truth that doesn’t exist. Not inventing facts. But recognizing incomplete data, biased truth, bad “prompting”. Given the same, a human makes mistakes. So does AI. So AI is not an oracle, it is a smart coworker. And more:
It does require a different understanding of AI. Not as a panacea and oracle, telling an ultimate truth that doesn’t exist. Not inventing facts. But recognizing incomplete data, biased truth, bad “prompting”. Given the same, a human makes mistakes. So does AI. So AI is not an oracle, it is a smart coworker. And more: The findings already: It’s more “human” than you might think, less a “super computer”. Just for comparison: Human brain can hold 3-5 “items” in it’s working, it’s short-term memory (
The findings already: It’s more “human” than you might think, less a “super computer”. Just for comparison: Human brain can hold 3-5 “items” in it’s working, it’s short-term memory (
 In 2008, so more than 15 years ago, I publicly asked the question: If the human brain has less ganglia than the world wide web (at the time already) had nodes, if the internet would have developed or would develop “sentience”, “self-recognition”, how would we know? Would we even know? And if we would know, would we be able to hedge it? It has no resemblance of Asimov’s Robot Laws, which were insufficient from the outset and not applicable anyway if not instilled at the core. My hope goes towards Heinlein’s AI-concepts, of evolving (like what we see today) like Mycroft Holmes from
In 2008, so more than 15 years ago, I publicly asked the question: If the human brain has less ganglia than the world wide web (at the time already) had nodes, if the internet would have developed or would develop “sentience”, “self-recognition”, how would we know? Would we even know? And if we would know, would we be able to hedge it? It has no resemblance of Asimov’s Robot Laws, which were insufficient from the outset and not applicable anyway if not instilled at the core. My hope goes towards Heinlein’s AI-concepts, of evolving (like what we see today) like Mycroft Holmes from 
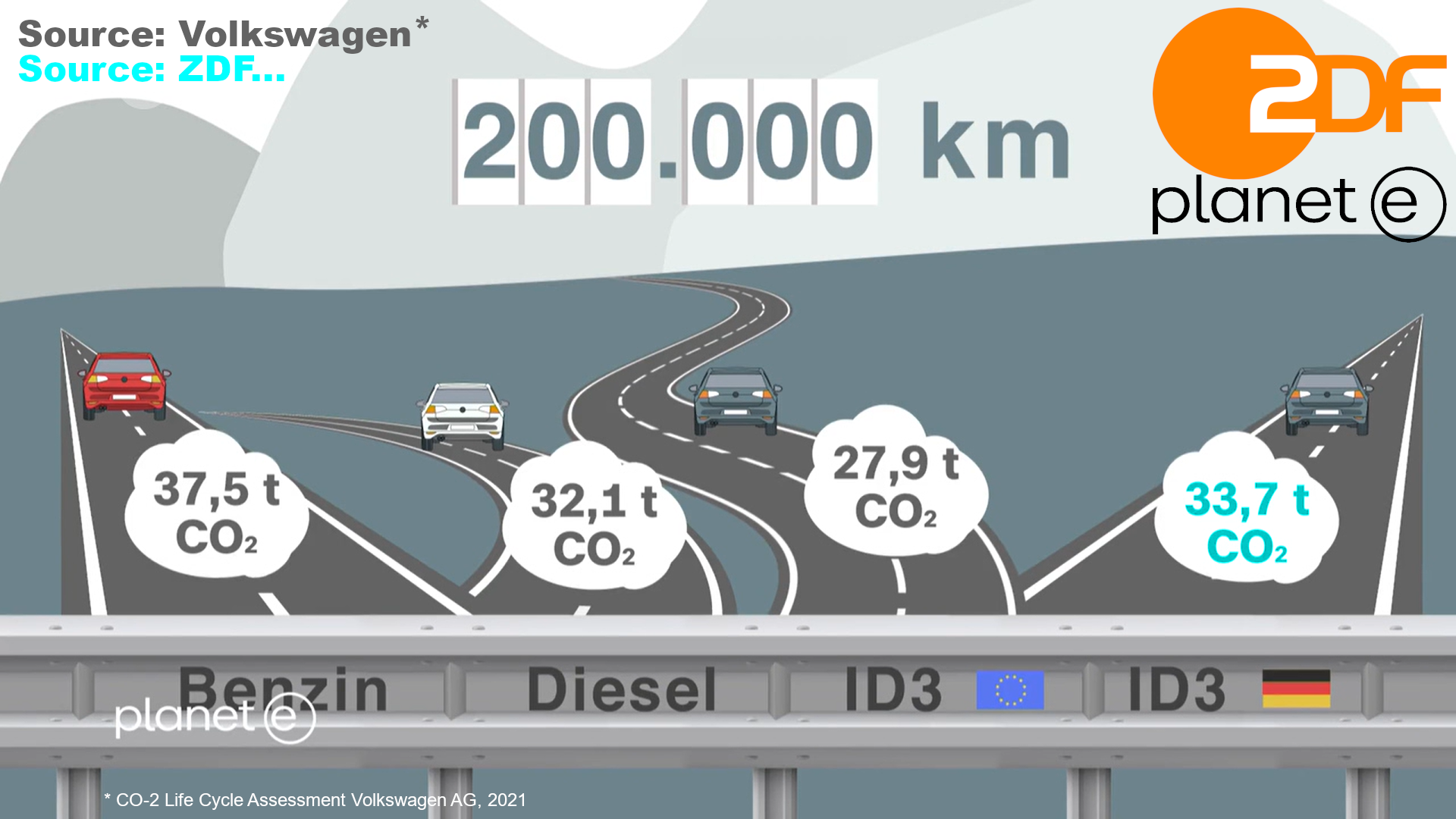

 Loading takes 30 minutes fast charging (high strain on the battery, shortened life-expectancy) to about four hours in average (German Automobile Club ADAC). Frequently a problem during summer vacation, long lines of EVs (electric vehicles) waiting for their turn at the charging station. Then sitting at the truck stop for three, four hours before they can continue. Good business for the truck stop.
Loading takes 30 minutes fast charging (high strain on the battery, shortened life-expectancy) to about four hours in average (German Automobile Club ADAC). Frequently a problem during summer vacation, long lines of EVs (electric vehicles) waiting for their turn at the charging station. Then sitting at the truck stop for three, four hours before they can continue. Good business for the truck stop.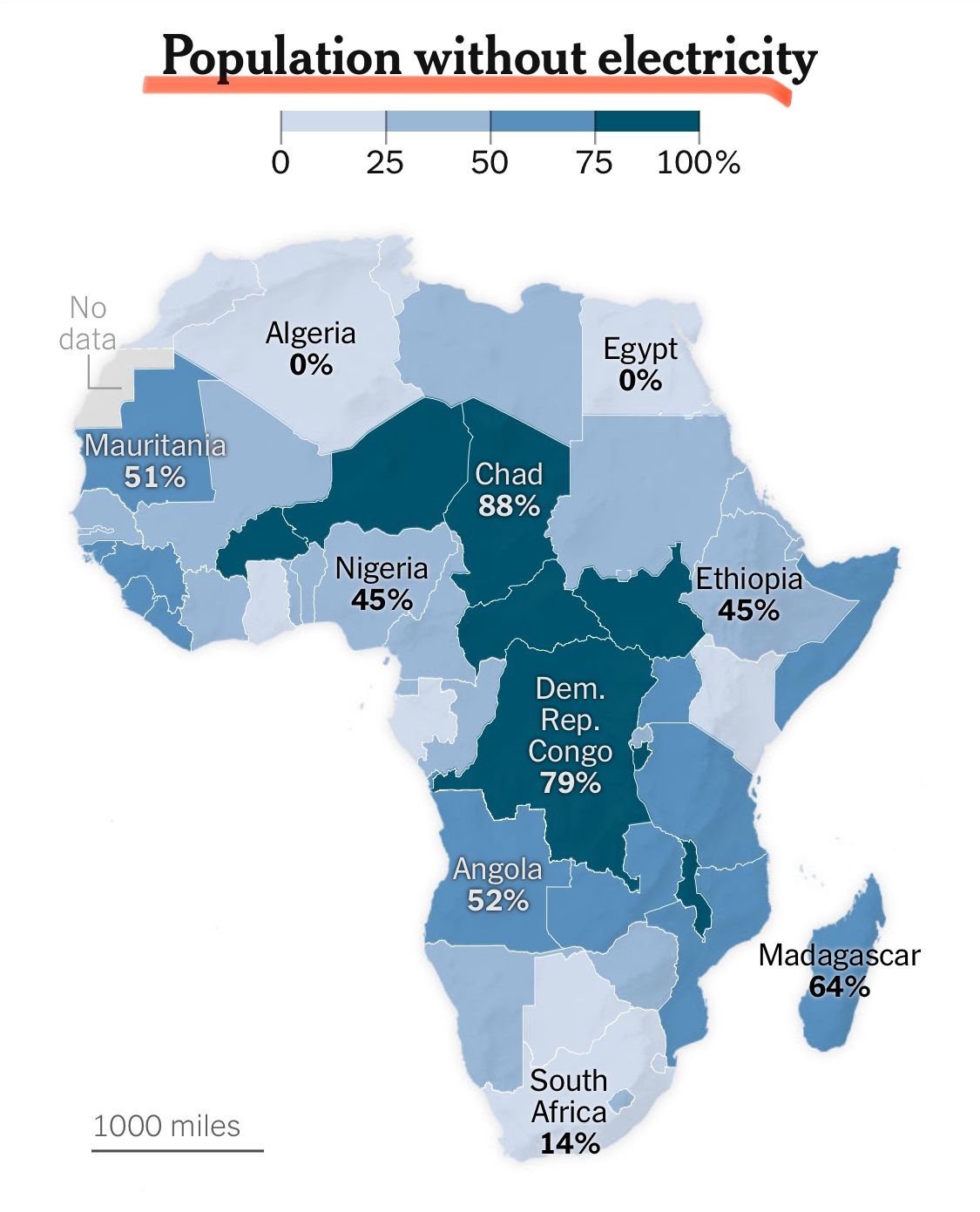
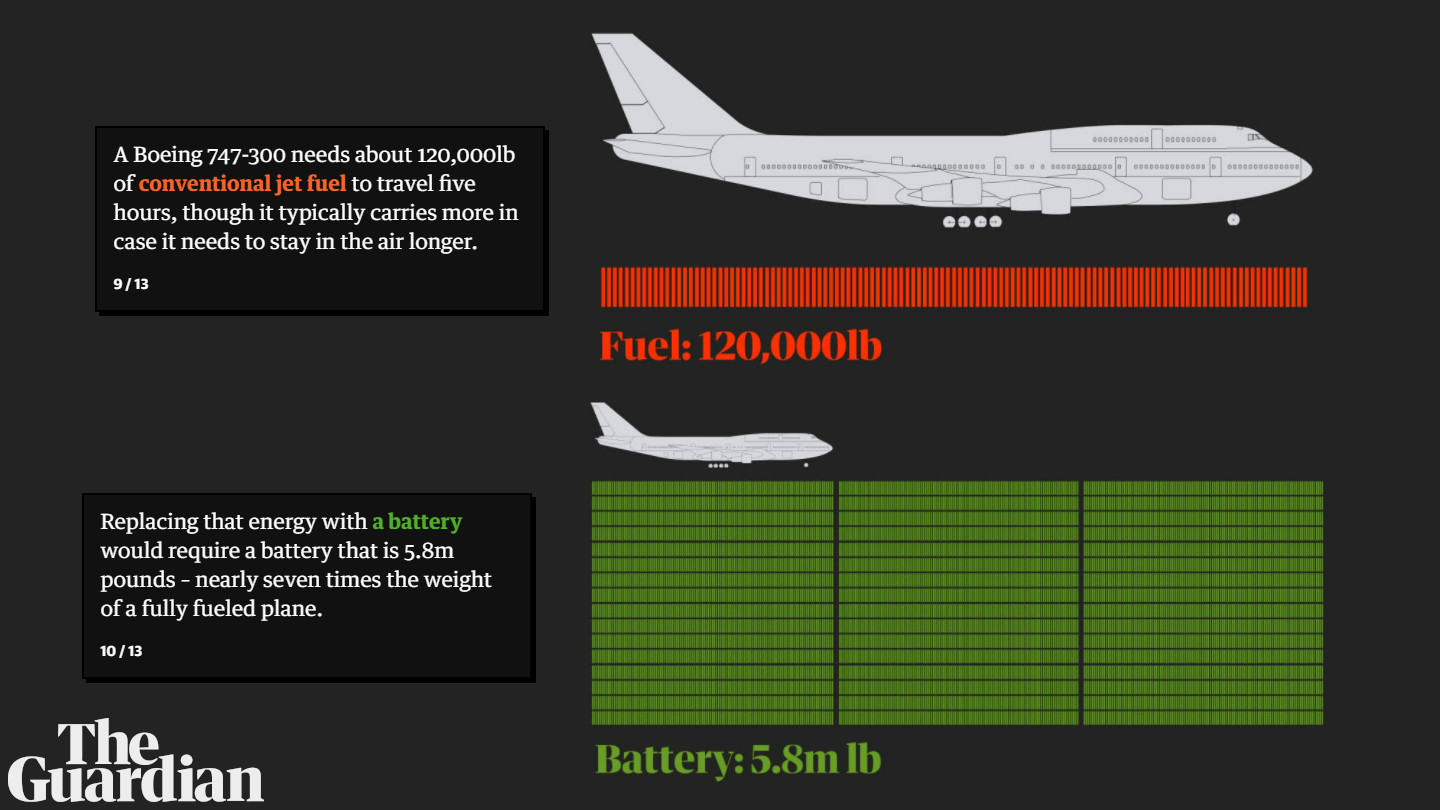 The issue with electric flight remains very much as it was back in 2019, when Boeing pulled out of their venture with
The issue with electric flight remains very much as it was back in 2019, when Boeing pulled out of their venture with  I do hope you know my Whitepaper on
I do hope you know my Whitepaper on  As I wrote some years ago in my whitepaper about the
As I wrote some years ago in my whitepaper about the  What truly upsets me, is the likes of World Fund or European Investment Bank disqualifying Kolibri for our strategy based on green SynFuels, as their “
What truly upsets me, is the likes of World Fund or European Investment Bank disqualifying Kolibri for our strategy based on green SynFuels, as their “ Green vs. Grid Energy
Green vs. Grid Energy Though just as others, they keep denying to have any closer look at our hard numbers. Numbers qualifying a profitability of the venture within three, 100% fossil-flying within about seven to eight years – still in the 2035 range! And while they fancy themselves for focusing on a 200 MT CPP (megaton carbon-capture potential), we talk about one gigaton fossil-fuel replacement, so a 1 000 MT CPP. Not by 2035, but in 2035. Doubling within the following three years on our 10-year plans.
Though just as others, they keep denying to have any closer look at our hard numbers. Numbers qualifying a profitability of the venture within three, 100% fossil-flying within about seven to eight years – still in the 2035 range! And while they fancy themselves for focusing on a 200 MT CPP (megaton carbon-capture potential), we talk about one gigaton fossil-fuel replacement, so a 1 000 MT CPP. Not by 2035, but in 2035. Doubling within the following three years on our 10-year plans.
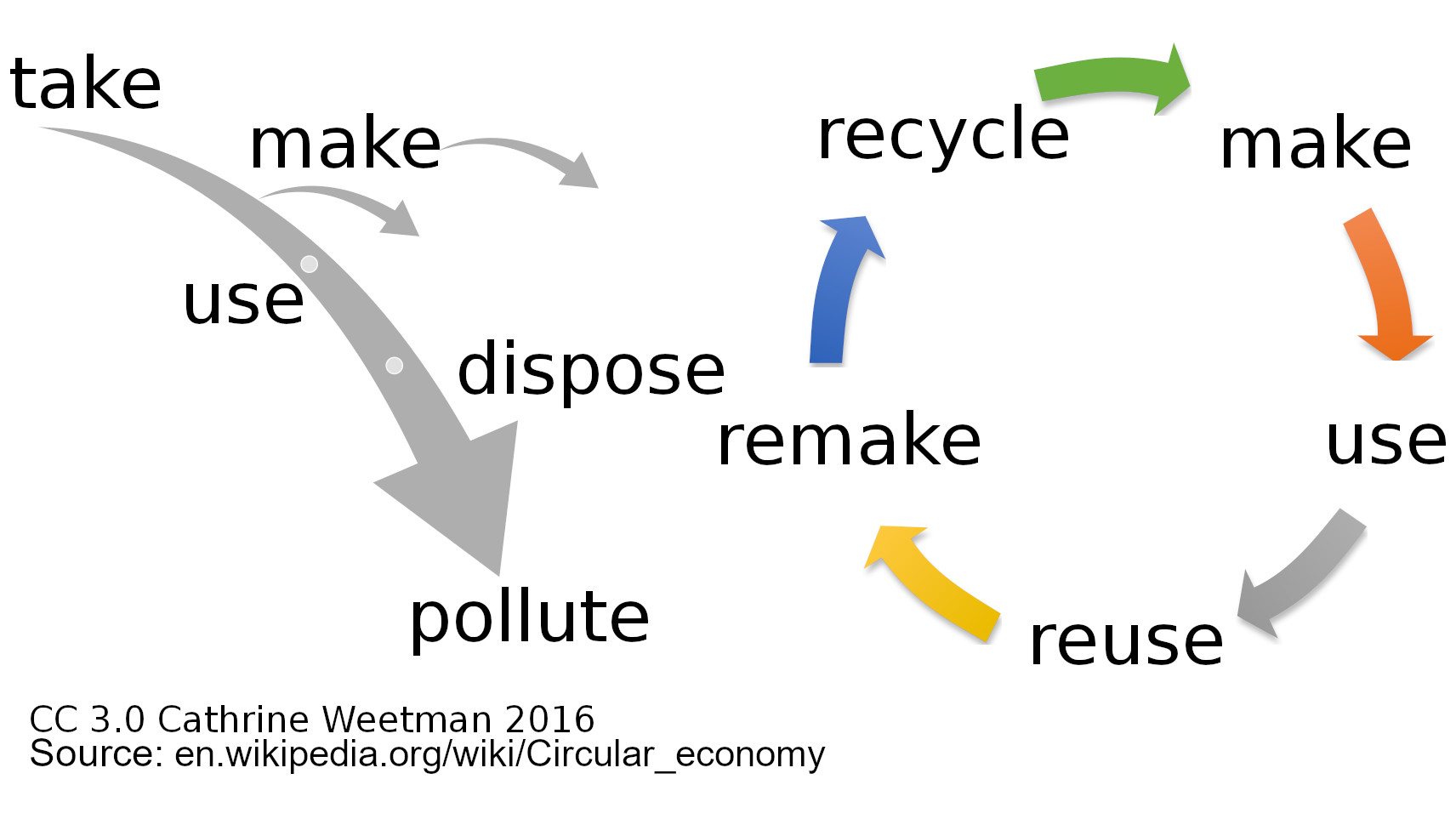

![“For those who agree or disagree, it is the exchange of ideas that broadens all of our knowledge” [Richard Eastman]](https://foodforthought.barthel.eu/wp-content/uploads/2016/08/eastman_quote.jpg)

 Again, I assume it’s something you heard from me before. For many years now, I restricted myself to 10 (ten) mailing lists. The RSS-feeds mostly dried out anyway. But I found it interesting to how many mailing lists I got “signed up”. No, I didn’t do myself. I simply got added to. Got to be kidding I thought when my (intentionally) unfiltered inbox (previously filtered) for those six weeks flooded my new mail app with 13 000 e-Mails. Excuse me? On about 45 days, that’s more than 280 mails a day?
Again, I assume it’s something you heard from me before. For many years now, I restricted myself to 10 (ten) mailing lists. The RSS-feeds mostly dried out anyway. But I found it interesting to how many mailing lists I got “signed up”. No, I didn’t do myself. I simply got added to. Got to be kidding I thought when my (intentionally) unfiltered inbox (previously filtered) for those six weeks flooded my new mail app with 13 000 e-Mails. Excuse me? On about 45 days, that’s more than 280 mails a day? Every day, I already limited my activity to LinkedIn to two hours a day. Before. Now those weeks, I made those two hours about every three to four days. And found I may have missed out thousands of “news” in my feed. But I started reaching out one-on-one which turned out rather more productive. Including feedback that those people from my network have not seen much of my posts in the past months. So what was that back in 2020 about the half-life of social media information?
Every day, I already limited my activity to LinkedIn to two hours a day. Before. Now those weeks, I made those two hours about every three to four days. And found I may have missed out thousands of “news” in my feed. But I started reaching out one-on-one which turned out rather more productive. Including feedback that those people from my network have not seen much of my posts in the past months. So what was that back in 2020 about the half-life of social media information?
 So while no longer prioritizing LinkedIn or the blog, I will keep writing the blog, for the mentioned reason. To summarize and organize my own thoughts. I also plan to experiment with a VLOG. But that’s neither on my priority list. So far I use my little studio for web-calls (WhatsApp, Google Meet, Zoom, etc.). Let’s see how that will go.
So while no longer prioritizing LinkedIn or the blog, I will keep writing the blog, for the mentioned reason. To summarize and organize my own thoughts. I also plan to experiment with a VLOG. But that’s neither on my priority list. So far I use my little studio for web-calls (WhatsApp, Google Meet, Zoom, etc.). Let’s see how that will go.
 This is another example how the
This is another example how the 

 While this is so long ago, many in our industry have forgotten that SABRE was the first computerized global network that allowed us long before the World Wide Web to go into a travel agency somewhere and book flights, later hotels and other travel services on the other side of the world. When I entered the industry back in 1987 at
While this is so long ago, many in our industry have forgotten that SABRE was the first computerized global network that allowed us long before the World Wide Web to go into a travel agency somewhere and book flights, later hotels and other travel services on the other side of the world. When I entered the industry back in 1987 at !["Do something about it when something "smells funny". Even if it's not on your job description, IT'S YOUR JOB." [Henna Inam]](https://foodforthought.barthel.eu/wp-content/uploads/2019/02/Inam-Henna-Its-Your-Job.jpg) Together with a colleague I became responsible point of contact for airlines, managing, explaining and mitigating the “booking discrepancies” in a pre-online world, when bookings were transferred by teletype (a telex like, but automated system), not in real time. Only inside Amadeus, real time was “normal”. After some years, the internal network of which I wasn’t part of established a “Product Management Flight”, taking over my colleagues and my responsibilities… By the time I’ve become a member of the local Airline Sales Representatives Association (ASRA), though that suddenly was considered as an overstepping on my responsibilities. Something I found and find a statement of total bureaucratics’ thinking. Many years later, that was why Henna Inam’s statement resonated so well with me.
Together with a colleague I became responsible point of contact for airlines, managing, explaining and mitigating the “booking discrepancies” in a pre-online world, when bookings were transferred by teletype (a telex like, but automated system), not in real time. Only inside Amadeus, real time was “normal”. After some years, the internal network of which I wasn’t part of established a “Product Management Flight”, taking over my colleagues and my responsibilities… By the time I’ve become a member of the local Airline Sales Representatives Association (ASRA), though that suddenly was considered as an overstepping on my responsibilities. Something I found and find a statement of total bureaucratics’ thinking. Many years later, that was why Henna Inam’s statement resonated so well with me. On research for the ASRA on my second “Airline Sales & e-Commerce”-presentation, a series covering GDS, Online Services like AOL or CompuServe, but also already the new “World Wide Web” (WWW), that ran annually for some 15 years, on the WWW which I still then accessed via a then new link by CompuServe, I stumbled across a single form field on a website that called itself the “Internet Travel Network”. It was really pioneering days, the Internet being something for student freaks… The form took a Sabre-command and returned the result, usually a flight availability. Or for the smarter of us also an air fares analysis result.
On research for the ASRA on my second “Airline Sales & e-Commerce”-presentation, a series covering GDS, Online Services like AOL or CompuServe, but also already the new “World Wide Web” (WWW), that ran annually for some 15 years, on the WWW which I still then accessed via a then new link by CompuServe, I stumbled across a single form field on a website that called itself the “Internet Travel Network”. It was really pioneering days, the Internet being something for student freaks… The form took a Sabre-command and returned the result, usually a flight availability. Or for the smarter of us also an air fares analysis result. In 1996, some four or six weeks before a milestone that changed our industry, we did by mistake do test bookings in the real-world system and booked up about a hundred Lufthansa flights with travelers called Test Tester… While that was far enough in the future and we could resolve the issue with Lufthansa, we were approached by Amadeus, that it was not acceptable to abuse their system like this and they would never, never ever approve of someone doing bookings on Amadeus through a web-page!! No f***ing way! Oh yes, we were in big trouble.
In 1996, some four or six weeks before a milestone that changed our industry, we did by mistake do test bookings in the real-world system and booked up about a hundred Lufthansa flights with travelers called Test Tester… While that was far enough in the future and we could resolve the issue with Lufthansa, we were approached by Amadeus, that it was not acceptable to abuse their system like this and they would never, never ever approve of someone doing bookings on Amadeus through a web-page!! No f***ing way! Oh yes, we were in big trouble. A friend, I came to trust, just recently called me a “visionary”, something I never call myself. When I learned the bells and whistles of “Economics” (Whole Sale & Foreign Sales), my instructor on business education was the boss of a large whole sale logistics center. He taught me to always think things through. What will be the repercussions of buying from the cheapest? Your product will loose in quality. But, he instilled that in me: There is always someone cheaper out there. And he also emphasized and taught me to leave the comfort zone of “we have always done it that way”. We must think outside the box and constantly strive to be better.
A friend, I came to trust, just recently called me a “visionary”, something I never call myself. When I learned the bells and whistles of “Economics” (Whole Sale & Foreign Sales), my instructor on business education was the boss of a large whole sale logistics center. He taught me to always think things through. What will be the repercussions of buying from the cheapest? Your product will loose in quality. But, he instilled that in me: There is always someone cheaper out there. And he also emphasized and taught me to leave the comfort zone of “we have always done it that way”. We must think outside the box and constantly strive to be better.




 OAG summarized on the
OAG summarized on the  This is one reason, I do not believe we can make
This is one reason, I do not believe we can make  To date, I am still working with consulting companies reviewing airline business plans. Aside the usual failure issues, size is a recurring issue. Another being the lack of fallback in case of flight disruptions, may they be caused by technical issues, weather or other events. Their focus on cheap “human resources” and missing team building results in friction and internal competition that further weakens their product offering.
To date, I am still working with consulting companies reviewing airline business plans. Aside the usual failure issues, size is a recurring issue. Another being the lack of fallback in case of flight disruptions, may they be caused by technical issues, weather or other events. Their focus on cheap “human resources” and missing team building results in friction and internal competition that further weakens their product offering.!["Our Obsession with technology will slow down the green transition.” [Lubomila Jordanova]](https://foodforthought.barthel.eu/wp-content/uploads/2021/11/Jordanova-Lubomila-Techfocus-slows-down-green-transition.jpg) Having been reminded again of
Having been reminded again of 


 In 2008, I developed another “disruptive” idea of a hydrogen-powered WIG, to promote the need to think sustainable on a global aviation conference. While it made it through viability study into serious negotiations by a tropical government and a major green fund, it fell victim to Lehman, but I still think it should have been developed. Though since
In 2008, I developed another “disruptive” idea of a hydrogen-powered WIG, to promote the need to think sustainable on a global aviation conference. While it made it through viability study into serious negotiations by a tropical government and a major green fund, it fell victim to Lehman, but I still think it should have been developed. Though since 
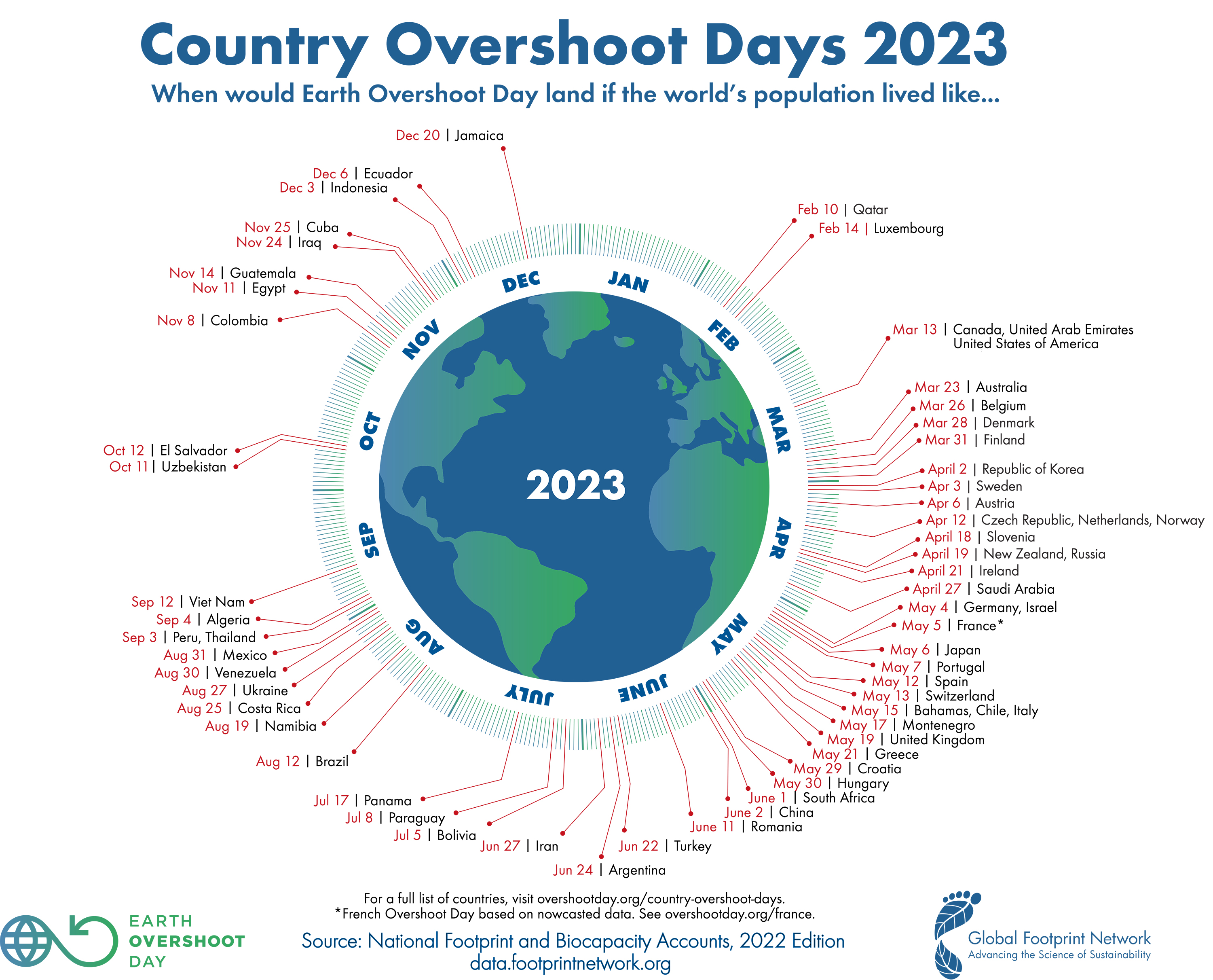

 Another issue that keeps coming up in my discussions is that we must stop competing on sustainable solutions. This is a major, not even just an industry or generational challenge. It’s a global one. So let’s stop competing and start joining forces! Back to my example of offshore wind farms and tidal energy turbines. Why not using them side-by-side in the same sea region we anyway impact by building those humongous wind farm structures? Why not using old Oil Rigs to apply tidal energy turbines, clean them, make them an artificial island structure for sea life (also arial one)?
Another issue that keeps coming up in my discussions is that we must stop competing on sustainable solutions. This is a major, not even just an industry or generational challenge. It’s a global one. So let’s stop competing and start joining forces! Back to my example of offshore wind farms and tidal energy turbines. Why not using them side-by-side in the same sea region we anyway impact by building those humongous wind farm structures? Why not using old Oil Rigs to apply tidal energy turbines, clean them, make them an artificial island structure for sea life (also arial one)?

 While we now suffer from decades of management misconception that everything must be subordinate to (quick) financial profit and that profits justify the means, we now start to recognize that “sustainability” must be a “shareholder’s value”, as long as “long-term success” (viability). My friends and audience do know I questioned the pure financially focused “shareholder value” for the past 25 years at minimum. And as an economist by “original” profession, I question all those dreamworld models that burn money in the next big hype.
While we now suffer from decades of management misconception that everything must be subordinate to (quick) financial profit and that profits justify the means, we now start to recognize that “sustainability” must be a “shareholder’s value”, as long as “long-term success” (viability). My friends and audience do know I questioned the pure financially focused “shareholder value” for the past 25 years at minimum. And as an economist by “original” profession, I question all those dreamworld models that burn money in the next big hype.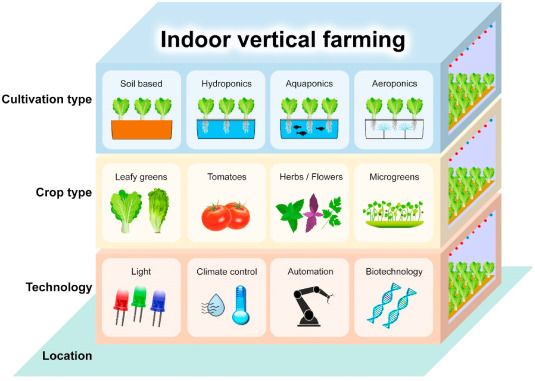 Given the current droughts and considering circular economy, thinking about greenhouses filling entire regions in Spain, I think we will need to invest into vertical farming. Given a “closed system” to improve the water usage. Reduce use of chemical fertilizers, herbicides and pesticides. Discussing with a startup recently, I was surprised on the efforts on seed sequence. Not for the plant or the soil, but to make sure the bees they use at all times find sufficient nectar.
Given the current droughts and considering circular economy, thinking about greenhouses filling entire regions in Spain, I think we will need to invest into vertical farming. Given a “closed system” to improve the water usage. Reduce use of chemical fertilizers, herbicides and pesticides. Discussing with a startup recently, I was surprised on the efforts on seed sequence. Not for the plant or the soil, but to make sure the bees they use at all times find sufficient nectar.


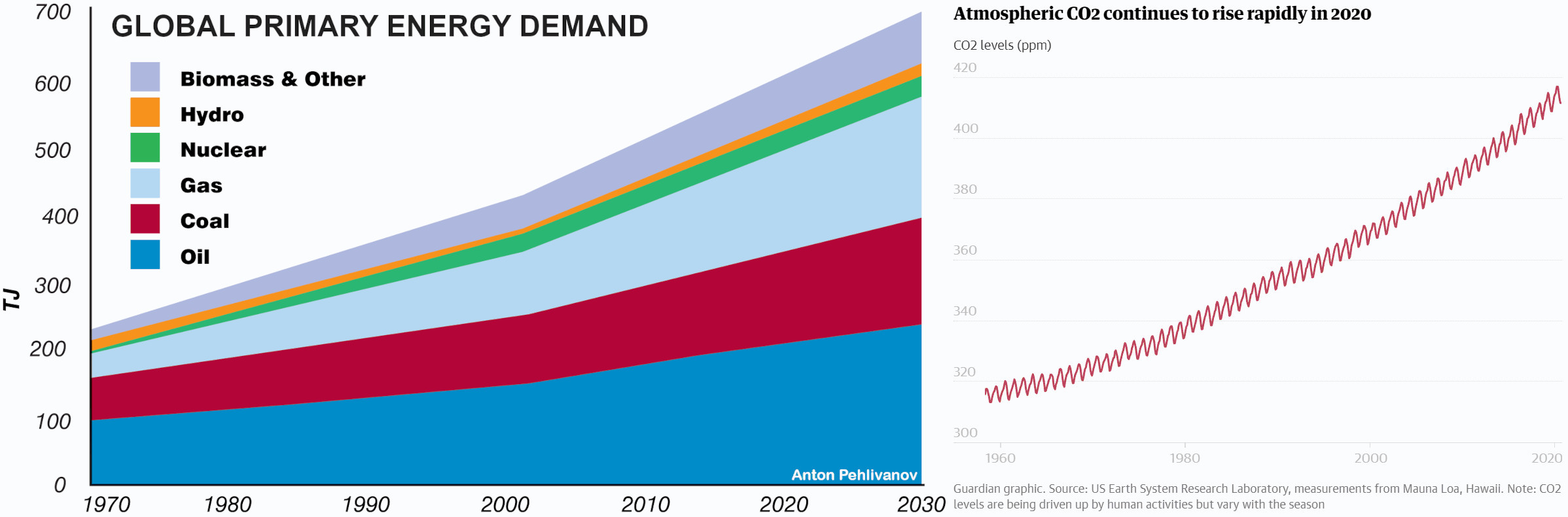
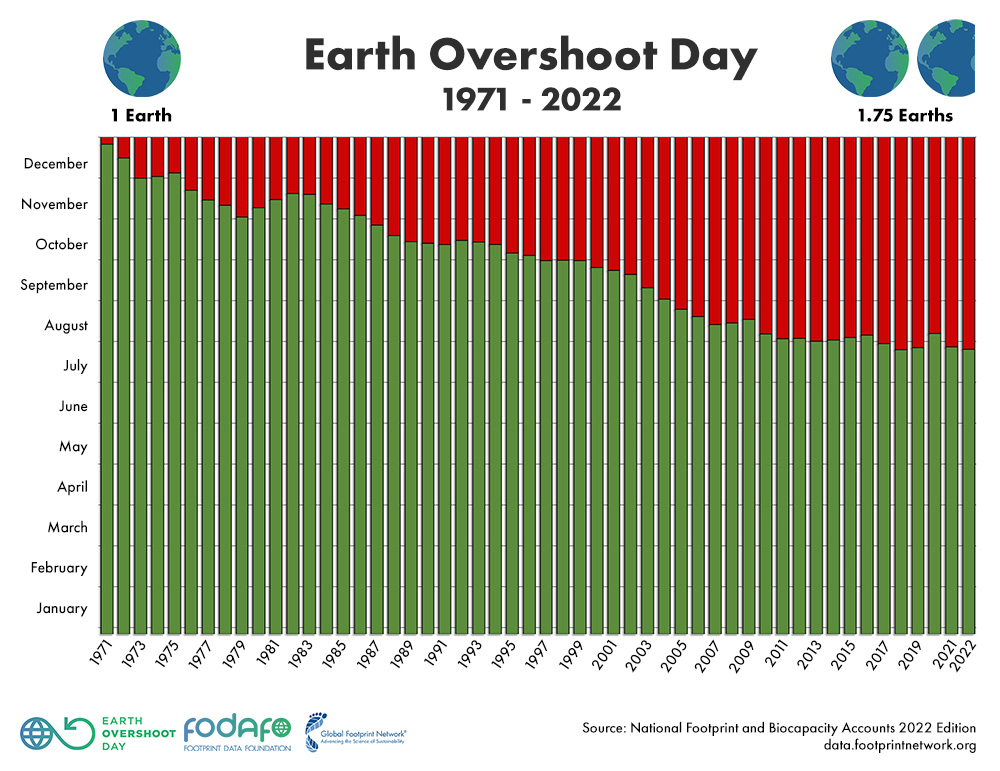
 There are many investments into small-scale change, with a focus on two to three years. That by itself should be an issue of concern for any real impact investor. As for climate change and sustainability that can only be a start. What is the 10 year outlook? What impact will it make by 2050?
There are many investments into small-scale change, with a focus on two to three years. That by itself should be an issue of concern for any real impact investor. As for climate change and sustainability that can only be a start. What is the 10 year outlook? What impact will it make by 2050? One of the main concerns we are faced with at Kolibri is our approach to sustainability. First of all, why would an airline turn sustainable, it’s heresy, ain’t it? And why would we pay salaries above country average? Maybe, because they are sustainable and secure the people’s motivation and loyalty?
One of the main concerns we are faced with at Kolibri is our approach to sustainability. First of all, why would an airline turn sustainable, it’s heresy, ain’t it? And why would we pay salaries above country average? Maybe, because they are sustainable and secure the people’s motivation and loyalty?