![“Our Heads Are Round so our Thoughts Can Change Direction” [Francis Picabia]](https://foodforthought.barthel.eu/wp-content/uploads/2021/10/Picabia-Francis-Round-Heads.jpg)

New York Times Headline: Delta Malfunction on Land Keeps a Fleet of Planes From the Sky
Voicing that opinion in combination with the related incidents for many years, this is just another example that we rely solely on cloud technologies without proper (working) backup or fallback systems.
Talking about “system failure”, it might not be related to technology here…
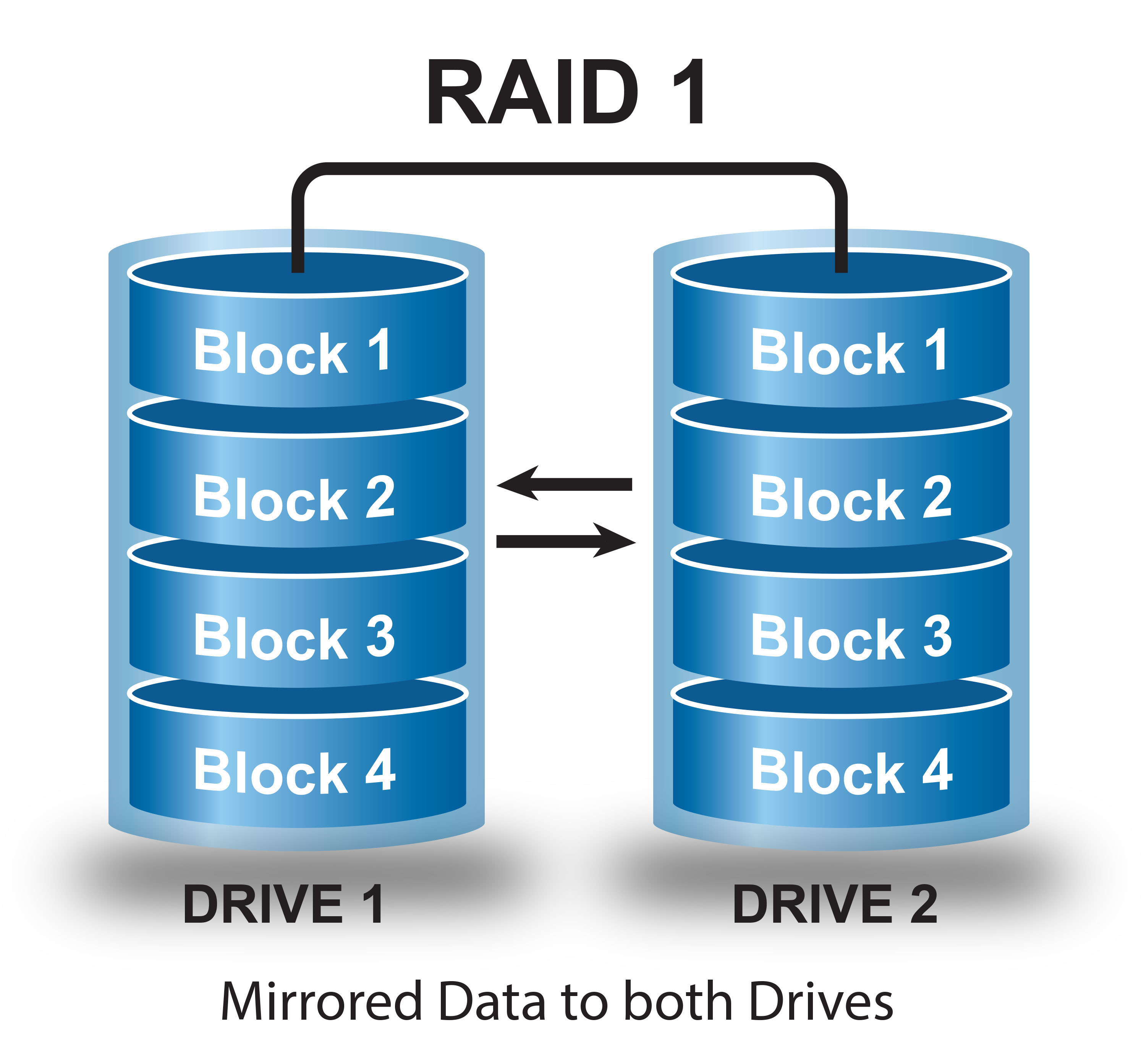 No matter if it was a power failure as initially stated or a malfunction of a power control module, it shows that Delta IT did not do basic precautionary homework. No backup power, no working (tested) system redundancy at a different server location. So one server location (Atlanta) fails and down goes Delta…? I can understand if a home location fails on backup and redundancy, but no serious company should rely on a single location. Redundant Array of Independent Disks (RAID) is a common precaution and on distributed systems can also operate at geographically different locations in order to assure that during an outage at one location, the other location seamlessly takes over.
No matter if it was a power failure as initially stated or a malfunction of a power control module, it shows that Delta IT did not do basic precautionary homework. No backup power, no working (tested) system redundancy at a different server location. So one server location (Atlanta) fails and down goes Delta…? I can understand if a home location fails on backup and redundancy, but no serious company should rely on a single location. Redundant Array of Independent Disks (RAID) is a common precaution and on distributed systems can also operate at geographically different locations in order to assure that during an outage at one location, the other location seamlessly takes over.The secondary system may be slower, less responsive, but it provides the backup.
And Delta cannot claim that to be the first time. The first time I had a similar case was with Northwest (now Delta) back in early 1990, where Northwest was one of the only flights leaving Frankfurt on time during a system outage, as we issued boarding passes by hand, based on the passenger list printed the evening before… I think that was the last time no individually traveling passenger had to sit on the middle seat alone…
 Another example I keep referring to was the time in the later 90s, early 2000s during the infancy of online travel booking, when Lufthansa hat to shut down Expedia. As Expedia inquiries for flight availability paralyzed Lufthansa operations. Because from the old logic of the airline CRS (computer logic), the booking process prioritized operational processes. Expedia’s uncached availability requests to the Lufthansa hosts flooded the Lufthansa system to the point where no operational requests could be processed. Good night check-in, good night passenger manifests, good night operations.
Another example I keep referring to was the time in the later 90s, early 2000s during the infancy of online travel booking, when Lufthansa hat to shut down Expedia. As Expedia inquiries for flight availability paralyzed Lufthansa operations. Because from the old logic of the airline CRS (computer logic), the booking process prioritized operational processes. Expedia’s uncached availability requests to the Lufthansa hosts flooded the Lufthansa system to the point where no operational requests could be processed. Good night check-in, good night passenger manifests, good night operations.
In 2004, a system crash paralyzed Lufthansa, which I addressed in my blog about the St. Florian’s Principle: Oh Holy Dear St. Florian, don’t burn my house, take the neighbor’s one.
Those are just major ones, which became noticeable to me. Business Insider reports more cases with JetBlue, American and United. So now it’s Delta. But taken the speed of IT development and the increasing complexity of the systems used, I doubt it takes a long time to hear about more such crashes. Time for the airline IT to do it’s homework and make sure the host system (CRS) is redundant…
Food For Thought
Comments welcome
Comments
USA Today: Travel trouble? Here’s why your airline flight is delayed
Nicely posted under “money”. And this is true, the “core” system in about any “legacy airline” and even many of the “newcomers” are based on the TPF (Transaction Processing Facility), using “automated teletex” communication on standards that have been useful in the 1980s, called AIRIMP.
Instead of reengineering their tools to make use of modern 64bit technology, that base layer is 6 bit (64 characters max). That means: capital A-Z, 0-9. The remaining characters are used for command sequences. A Unicode front end on a 64-bit machine communicates with a translator software to translate to 6 bit for the CRS’s or GDS’s PNR, the “Passenger Name Record” (the booking). Same reason, why Tickets and Boarding passes don’t work with special characters, mixed case or character sets other than Latin. If they use mixed case someone has written an algorithm that converts the information or they maintain tables (i.e. with airport names).
And yes. That doesn’t make redundancy any easier…